





반응형
코쿤이 무엇인지 살펴보고 설치방법을 설명한다.
코쿤은 무엇인가?
XML 관련 기술중에서 필자가 관심을 갖는 것 중의 하나가 웹 출판 프레임워크인데, 다양한 웹 출판 프레임워크 중에서도 특히 많은 관심을 갖고 있는 것이 바로 아파치의 XML 프로젝트에서 개발하고 있는 코쿤(Cocoon)이다. 코쿤은 웹 출판 프레임워크에 필요한 다양한 기능을 제공하고 있으며, 또한 지속된 버전업을 통해서 안전성면에서도 다른 프레임워크를 앞서가고 있다. 이번 글에서는 코쿤에 대한 개략적인 내용에 대해서 살펴볼 것이며, 계속해서 3-4 차례에 걸쳐서 코쿤을 사용하는 방법에 대해서 살펴보도록 할 것이다.
아파치 코쿤은 서버 어플리케이션에서 XML과 XSLT 기술의 사용방법을 한단계 끌어올려준 웹 출판 프레임워크이다. 파이프라인 처리를 사용하여 성능과 확장성에 주안점을 두어 설계된 코쿤은 컨텐트, 로직, 스타일을 분리하여 유연한 웹 출판 환경을 제공하고 있다. 중앙집중화된 설정 시스템과 정교한 캐싱 기능이 이를 가능하게 해주며, 이는 견고한 XML 서버 어플리케이션을 개발하고 배포하고 유지하는 데 도움을 준다.
코쿤은 파일시스템, RDBMS, LDAP, 네이티브 XML 데이터베이스, 네트워크 기반의 데이터 자원등 거의 모든 종류의 데이터 자원을 사용할 수 있다. 또한 코쿤은 하나의 컨텐트를 HTML, WML, PDF, SVG, RTF와 같이 서로 다른 포맷으로 전송할 수 있는 기능을 제공한다. 코쿤은 현재 서블릿으로 실행할 수 있으며 또한 명령행을 통해서도 실행할 수 있다. 코쿤은 추상화된 환경에 기반하여 설계되었기 때문에, 여러분은 요구사항에 알맞게 자신만의 코쿤 실행 환경을 구현할 수 있다.
코쿤의 개발 계기
지금까지 웹을 유지해온 HTML은 구조적인 한계를 갖고 있다. 예를 들어, Apache Jakarta 프로젝트에 관심이 있는 독자들은 한두번쯤은 http://jakarta.apache.org 사이트를 방문해보았을 것이다. 이 사이트를 보면 누구라도 쉽게 사이트가 상단부분, 왼쪽편 메뉴, 뉴스, 상태로 구성되어 있다는 것을 알 수 있을 것이다. 하지만, 사이트의 HTML 소스 코드를 보면 무수히 많은 TABLE 태그와 중첩된 태그들 때문에 정확하게 각 부분을 구분하는 것이 쉽지 않을 것이다.
이렇게 HTML 코드만으로 데이터의 각 영역을 구분하는 것이 어려운 이유는 HTML 모델이 단순히 화면을 보여주는 데 초점을 맞추고 있기 때문이다. 즉, HTML 문서는 문서의 구조나 데이터의 관계와 같이 데이터의 구조에 대한 정보를 포함하고 있지 않다. HTML 문서를 분석해서 문서 내에 있는 각 데이터 간의 관계를 추출해낸다는 것은 거의 불가능한 것이다. 이는 다시 말하면 HTML 문서로부터 어떤 '의미'를 분석해낸다는 것이 불가능하다는 것이다.
이렇듯 표현을 중심으로 설계된 HTML과 달리 XML 규약은 애초부터 데이터를 표현하는 데 초점을 맞춰 개발되었다. XML 문서는 XML 규약에 정의된 규칙을 반드시 따라야 하며, 트리 구조로 쉽게 표현할 수 있다는 장점을 갖고 있다. XML 문서는 트리 구조를 사용하여 데이터의 구조를 원하는데로 구성할 수 있고, 표현과 관계없이 데이터만을 저장하고 있기 때문에, 출판 시스템에서 출력할 데이터를 체계적으로 저장할 수 있다. 예를 들어, 웹사이트를 나타내는 XML 문서는 다음과 같이 표현할 수 있을 것이다.
위 문서는 HTML과는 확연한 차이점을 나타내고 있다. 표현과 관련된 어떤 데이터도 포함하고 있지 않은 것을 알 수 있다. 위 문서의 의미는 누구나 어렵지 않게 분석해낼 수 있다. 그렇다면 이러한 XML 문서와 코쿤이 무슨 관계가 있을까? 코쿤은 바로 이 XML을 데이터로 사용하여 컨텐트를 다양한 방식으로 출판할 수 있도록 하고 있다. 이와 관련된 내용은 앞으로 글을 진행해나가면서 살펴볼 것이다.
역할 분담을 염두한 설계
코쿤이 갖는 가장 중요한 특징은 SoC(Separation of Concerns; 작업의 분리) 기반으로 설계했다는 점이다. SoC는 여러분들이 항상 고민해오던 것 중의 하나이다. (모든 사람이 같은 것은 아니면, 모든 사람이 같은 능력으로 같은 일을 수행할 수 있는 것도 아니다.) 같은 기술을 가진 사람을 같은 작업 그룹에 포함되도록 사람들을 분리함으로써 생산성을 증가시키고 관리 비용을 줄일 수 있다는 사실이 관찰되었는데, 물론, 이러한 효과는 각 그룹의 업무가 겹치지 않고 각 그룹의 능력과 업무를 명확하게 정의한 경우에만 나타난다.
코쿤은 웹 출판 시스템에 '계약 피라미드'를 적용하였다. 이 계약 피라미드는 다음 그림에서 볼 수 있듯이, 네 가지 주요 업무 영역과 각 업무 영역 사이의 5가지 관계로 표시된다.
코쿤은 단지 5가지의 관계를 통해서 이 네가지 작업을 구분할 수 있는 방법을 제공하도록 설계되었다. 주목할만한 점은 로직 부분과 스타일시트 부분은 아무런 관련도 없다는 것이다. 이렇게 함으로써 웹 사이트를 개발할 때 소요되는 디자이너와 개발자 사이의 상극 관계를 없애주었다.
실제로 코쿤은 개발자가 다루는 로직 부분과 디자이너가 다루는 스타일 부분을 서로 다른 파일에 저장하도록 하였으며, 이 두 그룹의 작업은 오직 가상의 라인(작업 사이의 관계)을 통해서만 연결될 수 있도록 하였다. 실제로 어떻게 코쿤이 각 작업들을 분리할 수 있도록 해 주는지는 앞으로 여러 차례에 걸쳐 구체적으로 살펴볼 것이다.
코쿤 설치하기
코쿤을 사용하려면, 먼저 코쿤을 설치해야 할 것이다. 코쿤의 설치 방법은 사용하는 서블릿 콘테이너에 따라, 또한 사용하는 JDK 버전에 따라 다르다. 따라서 이 글에서는 JDK 1.2와 1.3.1을 기준으로 설명할 것이다. JDK 1.4.0의 경우는 아직 코쿤 2가 올바르게 지원하고 있지 않기 때문에 JDK 1.4.0을 기준으로 한 설명은 생략하기로 한다. 또한 톰캣의 각 버전에 따라 설치하는 방법을 설명할 것이다.
시스템 요구사항
코쿤을 설치하기 위해서는 먼저 다음의 두 시스템이 설치되어 있어야 한다.
코쿤 구하기
http://xml.apache.org/cocoon/dist에서 가장 최신 버전의 바이너리 배포판과 소스 코드 배포판을 다운로드 할 수 있으며 그리고 CVS를 이용하여 소스 코드를 다운로드 받을 수 있다. 이 글에서는 바이너리 배포판을 중심으로 설명할 것이므로 http://xml.apache.org/cocoon/dist 사이트에서 바이너리 버전을 다운로드 받기 바란다. 참고로, 이 글을 쓸 때는 코쿤 2.0.2 버전인 cocoon-2.0.2-bin.zip 파일을 사용하였다.
환경 설정하기
코쿤을 실행하기 위해서는 먼저 JAVA_HOME 환경 변수를 JDK가 설치된 루트 디렉토리로 지정해주어야 한다. 단순히 다음과 같이 지정해주면 된다.
코쿤 설치하기
서블릿 엔진에 따라서 차이가 있긴 하지만, 대부분의 서블릿 엔진에서 코쿤을 설치하는 과정은 단순히 파일을 복사하는 과정으로 끝이난다. 이 글에서는 쉽게 구할 수 있는 톰캣과 레신을 기준으로 설치 방법을 설명하도록 하겠다.
톰캣 3.2.x 버전에 설치하기
톰캣 3.2.x 버전과 코쿤 2.0.2가 사용하는 XML 관련 API는 서로 버전이 다르기 때문에, 코쿤 2.0.2를 설치하려면 약간의 편법을 써야 한다. 설치하는 순서는 다음과 같다.
톰캣 3.3.x 버전에 설치하
톰캣 3.3.x 버전에서는 매우 쉽게 코쿤을 설치할 수 있다. 간단히 다음과 같은 순서로 설치해주면 된다.
톰캣 4.0과 톰캣 4.0.1 버전에 코쿤을 설치하는 과정은 톰캣 3.3.x 버전에 설치 과정과 완전히 같으며, 다음과 같은 순서로 코쿤을 설치하면 된다.
톰캣 4.0.3에 코쿤을 설치하려면 톰캣이 사용하는 파서를 코쿤에 포함된 파서로 변경해주어야 한다. 톰캣 4.0.3에 코쿤 2.0.2를 설치하는 과정은 다음과 같다.
레신 2.0.x 버전에 설치하기
레신 2.0.x 버전에서 설치하는 과정은 다음과 같다.
지금까지 코쿤의 설치 방법에 대해서 살펴보았으므로, 이제 코쿤 자체에 대한 내용을 살펴보기로 하자. 이 글에서는 코쿤 1.x 버전에 대해서는 언급하지 않을 것이며, 코쿤 2에 대해서만 살펴볼 것이다.
앞에서 언급했듯이 코쿤은 업무에 따른 역할을 분담할 수 있도록 설계되었다. 즉, 컨텐츠, 로직, 스타일 그리고 이 전체의 관리의 네 가지 업무를 구분하는데 초점을 맞춰 설계되었다. 또한 코쿤은 XML, RDBSM 등의 다양한 데이터 자원을 사용하여 컨텐츠를 출판할 수 있도록 하고 있다.
이처럼 역할의 분리와 다양한 데이터 타입을 사용할 수 있도록 하기 위해서 코쿤은 4 가지의 주요 요소를 사용하는데, 이들 네 가지 요소는 다음과 같다.
위 그림을 보면서 차례대로 각 요소의 관계를 살펴보도록 하자. 먼저 클라이언트로부터 요청이 들어오면 Generator는 기존에 존재하는 자원(XML 문서, 로직 쉬트, RDB 등)으로부터 XML 문서를 생성한다. 이렇게 해서 생성된 XML 문서는 Transformer에 전해진다. Transformer는 XML 문서와 스타일시트를 사용하여 변환 과정을 처리한다. 이 과정에서 새로운 문서가 생성된다. 이때 생성된 문서는 Aggregator에 전달되며, Aggregator는 다양한 자원을 통합한 후 Serializer에 전달한다. 그러면 최종적으로 Serializer는 Aggregator로부터 받은 자원을 클라이언트가 볼 수 있는 형태로 렌더링하여 전송한다.
코쿤 2는 이미 다양한 종류의 자원으로부터 XML 문서를 생성할 수 있는 Generator를 제공하고 있으며, 또한 XML/HTML/PDF/SVG 등 다양한 포맷을 위한 Transformer와 Aggregator, Serializer를 제공하고 있다. 따라서 코쿤 2가 제공하는 기본 기능만으로도 훌륭한 출판 사이트를 제작할 수 있다.
코쿤을 구성하고 있는 Generator, Transformer, Aggregator, Serializer는 코쿤2에 새롭게 추가된 사이트맵을 통해서 명시할 수 있으며, 또한, 사이트맵을 통해서 네 가지 구성 요소를 조합할 수 있다. 예를 들면 A 라는 자원을 B 라는 Generator를 통해서 XML로 생성한 다음, C라는 Tranformer를 사용하여 변환하고 그 다음 D라는 Serializer를 사용하여 클라이언트에 최종 출판물을 전송한다는 식으로 일련의 과정을 사이트맵에서 지정할 수 있다. 보다 정확하게 말해서 이러한 일련의 처리 과정은 파이프라인을 통해서 처리되는데, 파이프라인은 사이트맵에 명시된다. 결국 사이트맵을 통해서 코쿤의 모든 출판 과정이 처리된다고 생각하면 된다.
다음의 시퀀스 다이어그램은 클라이언트의 요청이 코쿤에서 어떤 순서로 처리되는 지를 보여주고 있다.
SiteMap은 사이트맵을 나타내고 Pipeline은 클라이언트의 요청이 처리되는 일련의 과정을 나타낸다. 하나의 사이트맵에는 다수의 파이프라인이 존재할 수 있으며, 사이트맵은 클라이언트의 요청에 따라 알맞은 파이프라인을 선택하여 클라이언트에 응답 메시지를 전송하게 된다.
파이프라인을 개념적으로 도식화하면 다음과 같다.
위 그림을 보면 Generator와 Transformer 그리고 Serializer 사이에 SAX를 사용하여 데이터를 전달하는 것을 알 수 있는 데, 이렇게 SAX를 선택한 이유는 처리속도를 높이기 위해서이다.
사이트맵과 XSP
코쿤이 단순히 (XSLT를 사용하여) XML을 다양한 형식의 문서로 변환해주는 데 그쳤다면 코쿤은 그저 유틸리티 정도의 프레임워크에 그쳤을 것이다. 하지만, 코쿤은 거기서 멈추지 않았다. 코쿤은 로직과 표현을 완벽하게 분리해주는 XSP라는 걸출한 스크립트를 제공하고 있으며, 코쿤 2부터는 프로그래머가 아닌 사람도 로직 컴포넌트와 XML 문서만으로 웹 사이트와 웹 어플리케이션을 작성할 수 있도록 해 주는 사이트맵 기능을 제공하고 있다.
사이트맵(Sitemap)
사이트 맵은 웹 출판과 관련된 모든 것들을 정리해 놓은 XML 파일로서, 파일명은 sitemap.xmap이다. 이 파일은 다음과 같은 요소에 대한 정의를 포함하고 있으며 각 요소를 어떻게 조립할지를 명시할 수 있다.
XSP(eXtensible Server Page)
XSP는 서버측의 스크립트로서 로직의 구현과 표현의 구현을 분리해주는 XML 문서이다. XSP의 처리 흐름은 다음 그림과 같다.
위 그림에서 page.xml은 데이터를 저장하고 있는 XML 문서이며, page-xsp.xsl은 로직을 저장하고 있는 로직시트 파일이다. 로직시트는 XSP에서 사용되는 로직 관련 태그를 사용하여 XML 데이터를 처리하며, XSP 처리 결과는 XML로 생성된다. XSP 처리 결과로 생성된 XML 파일은 스타일시트를 사용하여 실제로 출력될 포맷으로 변환된다. XSP에 대해서는 3번째 글에서 자세하게 살펴보도록 하겠다./p>
XML 변환 예제
지금까지 코쿤에 대한 기본 개념과 구조에 대해서 살펴봤는데 XML 문서를 HTML로 변환하는 과정을 통해서 간단하게나마 코쿤이 제공하는 출판 기능을 사용해보도록 하자. 먼저 사용할 XML 문서는 다음과 같다.
참고로 위 예제는 O'Reilly에서 출판된 'Java and XML 2nd'에 있는 코드이다. 위 XML 문서는 책의 목차를 보여주고 있다는 것을 예상할 수 있을 것이다. 이 XML 문서를 HTML로 변환해줄 XSL 파일은 다음과 같다.
앞의 XML 문서를 [톰캣]/webapps/cocoon 디렉토리에 contents.xml 로 저장하고, 뒤의 XSL 문서를 [톰캣]/webapps/cocoon/XSL/JavaXML.html.xsl로 저장하자.
contents.xml 파일에서 중요한 점은 contents.xml 파일을 처리할 때 사용되는 XSL 문서를 지정하고 있지 않다는 점이다. 실제로 XML 문서를 변환할 때 사용할 XSL 문서는 코쿤의 설정 파일인 sitemap.xmap 파일에서 지정하게 된다. 이 예제를 지정하기 위해서는 [톰캣]/webapps/cocoon/sitemap.xmap 파일에 다음의 내용을 추가하면 된다.
여기서 <map:match>는 클라이언트가 요청한 URI와의 매핑되는 조건을 입력하며, <map:generate>은 사용자의 요청에 대해서 사용할 Generator를 지정한다. src 속성의 값이 contents.xml 인데 이는 contents.xml을 사용하여 XML 문서를 생성한다는 것을 의미한다. <map:transform>은 Transformmer를 나타내는 것으로서 XML 문서를 변환할 때 사용할 XSL 문서를 지정한다. 마지막으로 <map:serialize>는 변환된 결과를 렌더링할때 사용되는 Serializer를 나타내는 것으로서, 여기서는 HTML 타입으로 출력해주는 Serializer를 선택하였다.
위 코드를 sitemap.xmap의 다음 부분에 삽입하도록 하자.
이제 필요한 설정은 끝났다. 톰캣을 실행하고 웹브라우저를 실행한 다음 웹브라우저의 주소란에 다음과 같은 URL을 입력해보자.
그러면 다음과 같은 결과 화면이 출력될 것이다.
위 출력 결과를 보면 XML 데이터가 HTML로 변환되어 출력된 것을 알 수 있다. 이 출력 결과에서 우리가 알아야 할 점은 컨텐트(XML 문서)와 컨텐트의 출판 방식(XSL 문서)이 서로 분리되어 있다는 점이다. 즉, 컨텐트 제작자와 디자이너의 작업 결과물이 서로 분리되어 있는 것이다. 그리고, 앞으로 살펴볼 XSP를 통해서 로직 부분이 처리되기 때문에, 컨텐트 제작자, 디자이너, 개발자의 작업이 서로 겹치지 않게 된다. 또한, 웹 사이트 관리자는 사이트맵을 통해서 컨텐트, 스타일, XSP를 알맞게 조합할 수 있다. 즉, 코쿤을 사용함으로써 완벽한 업무 분담이 이루어질 수 있는 것이다.
참고로 웹브라우저에 입력한 URL을 보면 contents.xml이 아닌 contents.html을 요청한 것을 알 수 있다. 즉, 클라이언트는 응답결과가 XML을 변환한 문서라는 것을 알 수 없는 것이다. 이처럼 원본 데이터에 대한 정보를 숨길 수 있는 것도 웹 사이트를 운영하는데 있어 유용한 기능중의 하나이다.
결론
이번 글에서는 코쿤에 대한 개략적인 설명과 설치 방법, 그리고 간단하게 나마 예제를 통해서 데이터와 표현부를 분리할 수 있다는 것도 알게 되었다. 다음에는 코쿤이 기본적으로 제공하는 사이트맵 컴포넌트인 Matcher, Generator, Transformer, Serializer에 대해서 살펴보고, 실제로 하나의 컨텐트를 다양한 방식으로 출판하는 예제도 살펴보도록 하자.
관련링크:
코쿤은 무엇인가?
XML 관련 기술중에서 필자가 관심을 갖는 것 중의 하나가 웹 출판 프레임워크인데, 다양한 웹 출판 프레임워크 중에서도 특히 많은 관심을 갖고 있는 것이 바로 아파치의 XML 프로젝트에서 개발하고 있는 코쿤(Cocoon)이다. 코쿤은 웹 출판 프레임워크에 필요한 다양한 기능을 제공하고 있으며, 또한 지속된 버전업을 통해서 안전성면에서도 다른 프레임워크를 앞서가고 있다. 이번 글에서는 코쿤에 대한 개략적인 내용에 대해서 살펴볼 것이며, 계속해서 3-4 차례에 걸쳐서 코쿤을 사용하는 방법에 대해서 살펴보도록 할 것이다.
아파치 코쿤은 서버 어플리케이션에서 XML과 XSLT 기술의 사용방법을 한단계 끌어올려준 웹 출판 프레임워크이다. 파이프라인 처리를 사용하여 성능과 확장성에 주안점을 두어 설계된 코쿤은 컨텐트, 로직, 스타일을 분리하여 유연한 웹 출판 환경을 제공하고 있다. 중앙집중화된 설정 시스템과 정교한 캐싱 기능이 이를 가능하게 해주며, 이는 견고한 XML 서버 어플리케이션을 개발하고 배포하고 유지하는 데 도움을 준다.
코쿤은 파일시스템, RDBMS, LDAP, 네이티브 XML 데이터베이스, 네트워크 기반의 데이터 자원등 거의 모든 종류의 데이터 자원을 사용할 수 있다. 또한 코쿤은 하나의 컨텐트를 HTML, WML, PDF, SVG, RTF와 같이 서로 다른 포맷으로 전송할 수 있는 기능을 제공한다. 코쿤은 현재 서블릿으로 실행할 수 있으며 또한 명령행을 통해서도 실행할 수 있다. 코쿤은 추상화된 환경에 기반하여 설계되었기 때문에, 여러분은 요구사항에 알맞게 자신만의 코쿤 실행 환경을 구현할 수 있다.
코쿤의 개발 계기
지금까지 웹을 유지해온 HTML은 구조적인 한계를 갖고 있다. 예를 들어, Apache Jakarta 프로젝트에 관심이 있는 독자들은 한두번쯤은 http://jakarta.apache.org 사이트를 방문해보았을 것이다. 이 사이트를 보면 누구라도 쉽게 사이트가 상단부분, 왼쪽편 메뉴, 뉴스, 상태로 구성되어 있다는 것을 알 수 있을 것이다. 하지만, 사이트의 HTML 소스 코드를 보면 무수히 많은 TABLE 태그와 중첩된 태그들 때문에 정확하게 각 부분을 구분하는 것이 쉽지 않을 것이다.
이렇게 HTML 코드만으로 데이터의 각 영역을 구분하는 것이 어려운 이유는 HTML 모델이 단순히 화면을 보여주는 데 초점을 맞추고 있기 때문이다. 즉, HTML 문서는 문서의 구조나 데이터의 관계와 같이 데이터의 구조에 대한 정보를 포함하고 있지 않다. HTML 문서를 분석해서 문서 내에 있는 각 데이터 간의 관계를 추출해낸다는 것은 거의 불가능한 것이다. 이는 다시 말하면 HTML 문서로부터 어떤 '의미'를 분석해낸다는 것이 불가능하다는 것이다.
이렇듯 표현을 중심으로 설계된 HTML과 달리 XML 규약은 애초부터 데이터를 표현하는 데 초점을 맞춰 개발되었다. XML 문서는 XML 규약에 정의된 규칙을 반드시 따라야 하며, 트리 구조로 쉽게 표현할 수 있다는 장점을 갖고 있다. XML 문서는 트리 구조를 사용하여 데이터의 구조를 원하는데로 구성할 수 있고, 표현과 관계없이 데이터만을 저장하고 있기 때문에, 출판 시스템에서 출력할 데이터를 체계적으로 저장할 수 있다. 예를 들어, 웹사이트를 나타내는 XML 문서는 다음과 같이 표현할 수 있을 것이다.
<?xml version="1.0" encoding="euc-kr"?>
<!DOCTYPE ... >
<site>
<title>한국의 미</title>
<top>
<logo-image>km.gif"</logo-image>
<top-menus>
</top-menus>
</top>
<leftside>
<menus>
<menu-item label='한국에 대하여' link='/about/korea.html' />
<menu-item label='2002 월드컵' link='/about/2002.html' />
</menus>
</leftside>
<content>
</content>
<copyright>
©right;
</copyright>
</site>
<!DOCTYPE ... >
<site>
<title>한국의 미</title>
<top>
<logo-image>km.gif"</logo-image>
<top-menus>
</top-menus>
</top>
<leftside>
<menus>
<menu-item label='한국에 대하여' link='/about/korea.html' />
<menu-item label='2002 월드컵' link='/about/2002.html' />
</menus>
</leftside>
<content>
</content>
<copyright>
©right;
</copyright>
</site>
위 문서는 HTML과는 확연한 차이점을 나타내고 있다. 표현과 관련된 어떤 데이터도 포함하고 있지 않은 것을 알 수 있다. 위 문서의 의미는 누구나 어렵지 않게 분석해낼 수 있다. 그렇다면 이러한 XML 문서와 코쿤이 무슨 관계가 있을까? 코쿤은 바로 이 XML을 데이터로 사용하여 컨텐트를 다양한 방식으로 출판할 수 있도록 하고 있다. 이와 관련된 내용은 앞으로 글을 진행해나가면서 살펴볼 것이다.
역할 분담을 염두한 설계
코쿤이 갖는 가장 중요한 특징은 SoC(Separation of Concerns; 작업의 분리) 기반으로 설계했다는 점이다. SoC는 여러분들이 항상 고민해오던 것 중의 하나이다. (모든 사람이 같은 것은 아니면, 모든 사람이 같은 능력으로 같은 일을 수행할 수 있는 것도 아니다.) 같은 기술을 가진 사람을 같은 작업 그룹에 포함되도록 사람들을 분리함으로써 생산성을 증가시키고 관리 비용을 줄일 수 있다는 사실이 관찰되었는데, 물론, 이러한 효과는 각 그룹의 업무가 겹치지 않고 각 그룹의 능력과 업무를 명확하게 정의한 경우에만 나타난다.
코쿤은 웹 출판 시스템에 '계약 피라미드'를 적용하였다. 이 계약 피라미드는 다음 그림에서 볼 수 있듯이, 네 가지 주요 업무 영역과 각 업무 영역 사이의 5가지 관계로 표시된다.
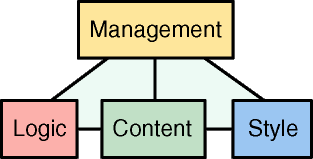
코쿤은 단지 5가지의 관계를 통해서 이 네가지 작업을 구분할 수 있는 방법을 제공하도록 설계되었다. 주목할만한 점은 로직 부분과 스타일시트 부분은 아무런 관련도 없다는 것이다. 이렇게 함으로써 웹 사이트를 개발할 때 소요되는 디자이너와 개발자 사이의 상극 관계를 없애주었다.
실제로 코쿤은 개발자가 다루는 로직 부분과 디자이너가 다루는 스타일 부분을 서로 다른 파일에 저장하도록 하였으며, 이 두 그룹의 작업은 오직 가상의 라인(작업 사이의 관계)을 통해서만 연결될 수 있도록 하였다. 실제로 어떻게 코쿤이 각 작업들을 분리할 수 있도록 해 주는지는 앞으로 여러 차례에 걸쳐 구체적으로 살펴볼 것이다.
코쿤 설치하기
코쿤을 사용하려면, 먼저 코쿤을 설치해야 할 것이다. 코쿤의 설치 방법은 사용하는 서블릿 콘테이너에 따라, 또한 사용하는 JDK 버전에 따라 다르다. 따라서 이 글에서는 JDK 1.2와 1.3.1을 기준으로 설명할 것이다. JDK 1.4.0의 경우는 아직 코쿤 2가 올바르게 지원하고 있지 않기 때문에 JDK 1.4.0을 기준으로 한 설명은 생략하기로 한다. 또한 톰캣의 각 버전에 따라 설치하는 방법을 설명할 것이다.
시스템 요구사항
코쿤을 설치하기 위해서는 먼저 다음의 두 시스템이 설치되어 있어야 한다.
- 1.2 이상의 버전과 호환되는 자바 가상 머신. 단 1.4.0 제외
- 서블릿 2.2를 지원하는 서블릿 엔진
코쿤 구하기
http://xml.apache.org/cocoon/dist에서 가장 최신 버전의 바이너리 배포판과 소스 코드 배포판을 다운로드 할 수 있으며 그리고 CVS를 이용하여 소스 코드를 다운로드 받을 수 있다. 이 글에서는 바이너리 배포판을 중심으로 설명할 것이므로 http://xml.apache.org/cocoon/dist 사이트에서 바이너리 버전을 다운로드 받기 바란다. 참고로, 이 글을 쓸 때는 코쿤 2.0.2 버전인 cocoon-2.0.2-bin.zip 파일을 사용하였다.
환경 설정하기
코쿤을 실행하기 위해서는 먼저 JAVA_HOME 환경 변수를 JDK가 설치된 루트 디렉토리로 지정해주어야 한다. 단순히 다음과 같이 지정해주면 된다.
[Win32] C:\> SET JAVA_HOME=c:\jdk1.3.1
[Linux] $ export JAVA_HOME=/usr/local/jdk1.3.1
[Linux] $ export JAVA_HOME=/usr/local/jdk1.3.1
코쿤 설치하기
서블릿 엔진에 따라서 차이가 있긴 하지만, 대부분의 서블릿 엔진에서 코쿤을 설치하는 과정은 단순히 파일을 복사하는 과정으로 끝이난다. 이 글에서는 쉽게 구할 수 있는 톰캣과 레신을 기준으로 설치 방법을 설명하도록 하겠다.
톰캣 3.2.x 버전에 설치하기
톰캣 3.2.x 버전과 코쿤 2.0.2가 사용하는 XML 관련 API는 서로 버전이 다르기 때문에, 코쿤 2.0.2를 설치하려면 약간의 편법을 써야 한다. 설치하는 순서는 다음과 같다.
- [톰캣]/lib/jaxp.jar 파일을 삭제한다.
- [톰캣]/lib/parser.jar 파일의 이름을 [톰캣]/lib/zparser.jar로 변경해준다.
- [코쿤소스코드버전배포판]/lib/core 디렉토리에 있는 xercesImpl-2.0.0.jar 파일과 xml-apis.jar 파일을 [톰캣]/lib 디렉토리에 복사해준다.
- [코쿤바이너리배포판]/cocoon.war 파일을 [톰캣]/webapps 디렉토리에 복사한다.
- 톰캣을 시작한다. 6. http://localhost:8080/cocoon에 연결해서 코쿤이 올바르게 실행되는 지 확인한다.
톰캣 3.3.x 버전에 설치하
톰캣 3.3.x 버전에서는 매우 쉽게 코쿤을 설치할 수 있다. 간단히 다음과 같은 순서로 설치해주면 된다.
- [코쿤바이너리배포판]/cocoon.war 파일을 [톰캣]/webapps 디렉토리에 복사한다.
- 톰캣을 시작한다.
- http://localhost:8080/cocoon에 연결해서 코쿤이 올바르게 실행되는 지 확인한다.
톰캣 4.0과 톰캣 4.0.1 버전에 코쿤을 설치하는 과정은 톰캣 3.3.x 버전에 설치 과정과 완전히 같으며, 다음과 같은 순서로 코쿤을 설치하면 된다.
- [코쿤바이너리배포판]/cocoon.war 파일을 [톰캣]/webapps 디렉토리에 복사한다.
- 톰캣을 시작한다.
- http://localhost:8080/cocoon에 연결해서 코쿤이 올바르게 실행되는 지 확인한다.
톰캣 4.0.3에 코쿤을 설치하려면 톰캣이 사용하는 파서를 코쿤에 포함된 파서로 변경해주어야 한다. 톰캣 4.0.3에 코쿤 2.0.2를 설치하는 과정은 다음과 같다.
- [톰캣]/common/lib/xerces.jar 파일을 삭제한다.
- [코쿤소스코드배포판]/lib/core 디렉토리에서 다음의 파일을 [톰캣]/common/lib 디렉토리에 복사한다.
- xalan-2.3.1.jar
- xercesImpl-2.0.0.jar
- xml-apis.jar
- [코쿤]/lib/optional/batik-all-1.5b1.jar 파일을 [톰캣]/common/lib 디렉토리에 복사한다.
- [코쿤소스코드배포판]/src/webapps/WEB-INF/web.xml 파일에 다음과 같이 extra-classpath 초기화 파라미터를 추가한다.
<init-param>
<param-name>extra-classpath</param-name>
<param-value>D:\jakarta-tomcat-4.0.3\common\lib\xalan-2.3.1.jar;
D:\jakarta-tomcat-4.0.3\common\lib\xercesImpl-2.0.0.jar;
D:\jakarta-tomcat-4.0.3\common\lib\xml-apis.jar;
D:\jakarta-tomcat-4.0.3\common\lib\batik-all-1.5b1.jar</param-value>
</init-param>
참고로 위에서 <param-value> 부분은 한 줄로 입력한 것이다. - 다음과 같이 build.bat을 실행하여 cocoon.war 파일을 생성한다.
build -Dinclude.webapp.libs=yes webapp
- [코쿤소스코드배포판]/build/cocoon/cocoon.war 파일을 [톰캣]/webapps 디렉토리에 복사한다.
- [톰캣]/webapps/cocoon 디렉토리를 생성한 후, [톰캣]/webapps/cocoon 디렉토리로 경로를 이동한다.
- 이 상태에서 다음과 같이 cocoon.war 파일의 압축을 [톰캣]/webapps/cocoon 디렉토리에 풀어준다.
D:\jakarta-tomcat-4.0.3\webapps\cocoon> jar xvf ..\cocoon.war
- [톰캣]/webapps/cocoon/WEB-INF/lib 디렉토리에서 xalan-2.3.1, xercesImpl-2.0.0.jar, xml-apis.jar 그리고 batik-all-1.5b1.jar 파일을 삭제한다.
- 톰캣을 시작한다.
- http://localhost:8080/cocoon에 연결해서 코쿤이 올바르게 실행되는 지 확인한다.
레신 2.0.x 버전에 설치하기
레신 2.0.x 버전에서 설치하는 과정은 다음과 같다.
- [레신]/lib 디렉토리에 있는 jaxp.jar, dom.jar, sax.jar 파일을 삭제한다.
- [코쿤소스코드배포판]/lib/core 디렉토리의 xercesImpl-2.0.0.jar와 xml-apis.jar를 [레신]/lib 디렉토리에 복사한다.
- [코쿤바이너리배포판]/cocoon.war 파일을 [레신]/webapps 디렉토리에 복사한다.
- 레신을 시작한다.
- http://localhost:8080/cocoon에 연결해서 코쿤이 올바르게 실행되는 지 확인한다.
지금까지 코쿤의 설치 방법에 대해서 살펴보았으므로, 이제 코쿤 자체에 대한 내용을 살펴보기로 하자. 이 글에서는 코쿤 1.x 버전에 대해서는 언급하지 않을 것이며, 코쿤 2에 대해서만 살펴볼 것이다.
앞에서 언급했듯이 코쿤은 업무에 따른 역할을 분담할 수 있도록 설계되었다. 즉, 컨텐츠, 로직, 스타일 그리고 이 전체의 관리의 네 가지 업무를 구분하는데 초점을 맞춰 설계되었다. 또한 코쿤은 XML, RDBSM 등의 다양한 데이터 자원을 사용하여 컨텐츠를 출판할 수 있도록 하고 있다.
이처럼 역할의 분리와 다양한 데이터 타입을 사용할 수 있도록 하기 위해서 코쿤은 4 가지의 주요 요소를 사용하는데, 이들 네 가지 요소는 다음과 같다.
- Generator - 컨텐츠, 로직쉬트, RDB, 객체를 사용하여 XML 문서를 생성한다.
- Transformer - XML 문서를 또 다른 XML이나 객체로 변환한다.
- Aggregator - XML 문서를 조합한다.
- Serializer - XML을 렌더링(rendering)한다.
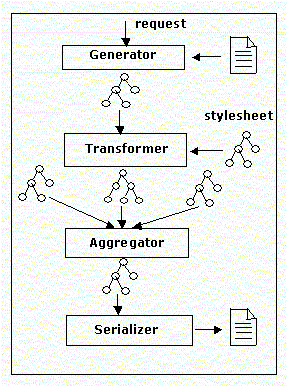
위 그림을 보면서 차례대로 각 요소의 관계를 살펴보도록 하자. 먼저 클라이언트로부터 요청이 들어오면 Generator는 기존에 존재하는 자원(XML 문서, 로직 쉬트, RDB 등)으로부터 XML 문서를 생성한다. 이렇게 해서 생성된 XML 문서는 Transformer에 전해진다. Transformer는 XML 문서와 스타일시트를 사용하여 변환 과정을 처리한다. 이 과정에서 새로운 문서가 생성된다. 이때 생성된 문서는 Aggregator에 전달되며, Aggregator는 다양한 자원을 통합한 후 Serializer에 전달한다. 그러면 최종적으로 Serializer는 Aggregator로부터 받은 자원을 클라이언트가 볼 수 있는 형태로 렌더링하여 전송한다.
코쿤 2는 이미 다양한 종류의 자원으로부터 XML 문서를 생성할 수 있는 Generator를 제공하고 있으며, 또한 XML/HTML/PDF/SVG 등 다양한 포맷을 위한 Transformer와 Aggregator, Serializer를 제공하고 있다. 따라서 코쿤 2가 제공하는 기본 기능만으로도 훌륭한 출판 사이트를 제작할 수 있다.
코쿤을 구성하고 있는 Generator, Transformer, Aggregator, Serializer는 코쿤2에 새롭게 추가된 사이트맵을 통해서 명시할 수 있으며, 또한, 사이트맵을 통해서 네 가지 구성 요소를 조합할 수 있다. 예를 들면 A 라는 자원을 B 라는 Generator를 통해서 XML로 생성한 다음, C라는 Tranformer를 사용하여 변환하고 그 다음 D라는 Serializer를 사용하여 클라이언트에 최종 출판물을 전송한다는 식으로 일련의 과정을 사이트맵에서 지정할 수 있다. 보다 정확하게 말해서 이러한 일련의 처리 과정은 파이프라인을 통해서 처리되는데, 파이프라인은 사이트맵에 명시된다. 결국 사이트맵을 통해서 코쿤의 모든 출판 과정이 처리된다고 생각하면 된다.
다음의 시퀀스 다이어그램은 클라이언트의 요청이 코쿤에서 어떤 순서로 처리되는 지를 보여주고 있다.
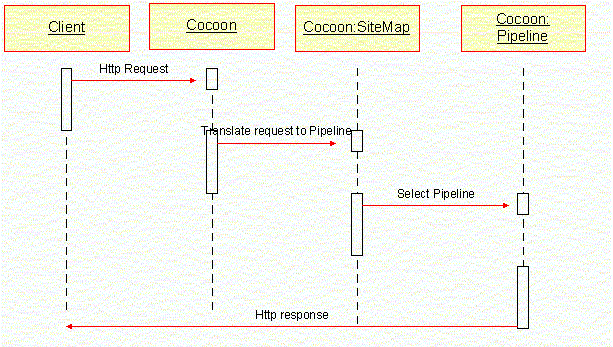
SiteMap은 사이트맵을 나타내고 Pipeline은 클라이언트의 요청이 처리되는 일련의 과정을 나타낸다. 하나의 사이트맵에는 다수의 파이프라인이 존재할 수 있으며, 사이트맵은 클라이언트의 요청에 따라 알맞은 파이프라인을 선택하여 클라이언트에 응답 메시지를 전송하게 된다.
파이프라인을 개념적으로 도식화하면 다음과 같다.
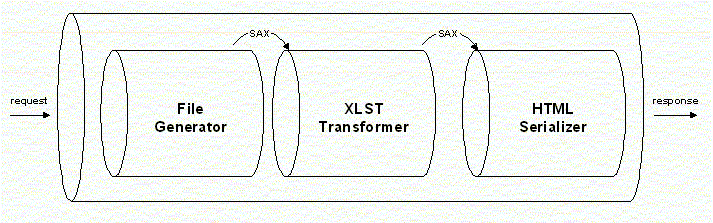
위 그림을 보면 Generator와 Transformer 그리고 Serializer 사이에 SAX를 사용하여 데이터를 전달하는 것을 알 수 있는 데, 이렇게 SAX를 선택한 이유는 처리속도를 높이기 위해서이다.
사이트맵과 XSP
코쿤이 단순히 (XSLT를 사용하여) XML을 다양한 형식의 문서로 변환해주는 데 그쳤다면 코쿤은 그저 유틸리티 정도의 프레임워크에 그쳤을 것이다. 하지만, 코쿤은 거기서 멈추지 않았다. 코쿤은 로직과 표현을 완벽하게 분리해주는 XSP라는 걸출한 스크립트를 제공하고 있으며, 코쿤 2부터는 프로그래머가 아닌 사람도 로직 컴포넌트와 XML 문서만으로 웹 사이트와 웹 어플리케이션을 작성할 수 있도록 해 주는 사이트맵 기능을 제공하고 있다.
사이트맵(Sitemap)
사이트 맵은 웹 출판과 관련된 모든 것들을 정리해 놓은 XML 파일로서, 파일명은 sitemap.xmap이다. 이 파일은 다음과 같은 요소에 대한 정의를 포함하고 있으며 각 요소를 어떻게 조립할지를 명시할 수 있다.
- 컴포넌트: Matcher, Generator, Transformer, Reader, Serializer, Selector, Action 등
- 뷰: 처리과정에서 생성된 XML에 대한 뷰를 정의한다.
- 리소스: 사이트맵 문서 내부에서만 사용가능하며, 파이프라인과 같은 방법으로 정의한다. 파이프라인은 필요에 따라 리소스를 사용할 수 있다.
- 액션: 런타임에 파라미터를 처리하기 위한 모듈
- 파이프라인: 파이프라인들을 정의한다.
XSP(eXtensible Server Page)
XSP는 서버측의 스크립트로서 로직의 구현과 표현의 구현을 분리해주는 XML 문서이다. XSP의 처리 흐름은 다음 그림과 같다.
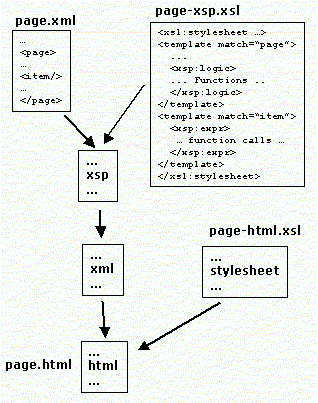
위 그림에서 page.xml은 데이터를 저장하고 있는 XML 문서이며, page-xsp.xsl은 로직을 저장하고 있는 로직시트 파일이다. 로직시트는 XSP에서 사용되는 로직 관련 태그를 사용하여 XML 데이터를 처리하며, XSP 처리 결과는 XML로 생성된다. XSP 처리 결과로 생성된 XML 파일은 스타일시트를 사용하여 실제로 출력될 포맷으로 변환된다. XSP에 대해서는 3번째 글에서 자세하게 살펴보도록 하겠다./p>
XML 변환 예제
지금까지 코쿤에 대한 기본 개념과 구조에 대해서 살펴봤는데 XML 문서를 HTML로 변환하는 과정을 통해서 간단하게나마 코쿤이 제공하는 출판 기능을 사용해보도록 하자. 먼저 사용할 XML 문서는 다음과 같다.
<?xml version="1.0"?>
<!DOCTYPE book SYSTEM "DTD/JavaXML.dtd">
<!-- Java and XML Contents -->
<book xmlns="http://www.oreilly.com/javaxml2"
xmlns:ora="http://www.oreilly.com"
>
<title ora:series="Java">Java and XML</title>
<!-- Chapter List -->
<contents>
<chapter title="Introduction" number="1">
<topic name="XML Matters" />
<topic name="What's Important" />
<topic name="The Essentials" />
<topic name="What's Next?" />
</chapter>
<chapter title="Nuts and Bolts" number="2">
<topic name="The Basics" />
<topic name="Constraints" />
<topic name="Transformations" />
<topic name="And More..." />
<topic name="What's Next?" />
</chapter>
<chapter title="SAX" number="3">
<topic name="Getting Prepared" />
<topic name="SAX Readers" />
<topic name="Content Handlers" />
<topic name="Gotcha!" />
<topic name="What's Next?" />
</chapter>
<chapter title="Advanced SAX" number="4">
<topic name="Properties and Features" />
<topic name="More Handlers" />
<topic name="Filters and Writers" />
<topic name="Even More Handlers" />
<topic name="Gotcha!" />
<topic name="What's Next?" />
</chapter>
<chapter title="DOM" number="5">
<topic name="The Document Object Model" />
<topic name="Serialization" />
<topic name="Mutability" />
<topic name="Gotcha!" />
<topic name="What's Next?" />
</chapter>
<chapter title="Advanced DOM" number="6">
<topic name="DOM and Mutation" />
<topic name="Namespaces and DOM Level 2" />
<topic name="DOM and HTML" />
<topic name="DOM Level 3" />
<topic name="Gotcha!" />
<topic name="What's Next?" />
</chapter>
<chapter title="JDOM" number="7">
<topic name="The Basics" />
<topic name="PropsToXML" />
<topic name="XMLProperties" />
<topic name="Is JDOM a Standard?" />
<topic name="Gotcha!" />
<topic name="What's Next?" />
</chapter>
<chapter title="Advanced JDOM" number="8">
<topic name="The Whole Ball of Wax" />
<topic name="JDOM and Factories" />
<topic name="Wrappers and Decorators" />
<topic name="Gotcha!" />
<topic name="What's Next?" />
</chapter>
<chapter title="JAXP" number="9">
<topic name="API or Abstraction?" />
<topic name="JAXP 1.0" />
<topic name="JAXP 1.1" />
<topic name="Gotcha!" />
<topic name="What's Next?" />
</chapter>
<chapter title="Web Publishing Frameworks" number="10">
<topic name="Selecting a Framework" />
<topic name="Installation" />
<topic name="Using a Publishing Framework" />
<topic name="XSP" />
<topic name="Cocoon 2.0 and Beyond" />
<topic name="What's Next?" />
</chapter>
<chapter title="XML-RPC" number="11">
<topic name="RPC Versus RMI" />
<topic name="Saying Hello" />
<topic name="The Real World" />
<topic name="What's Next?" />
</chapter>
<chapter title="SOAP" number="12">
<topic name="Starting Out" />
<topic name="Setting Up" />
<topic name="Getting Dirty" />
<topic name="Going Further" />
<topic name="What's Next?" />
</chapter>
<chapter title="Web Services" number="13">
<topic name="Web Services" />
<topic name="UDDI" />
<topic name="WSDL" />
<topic name="Putting It All Together" />
<topic name="What's Next?" />
</chapter>
<chapter title="Content Syndication" number="14">
<topic name="The Foobar Public Library" />
<topic name="mytechbooks.com" />
<topic name="Push Versus Pull" />
<topic name="What's Next?" />
</chapter>
<chapter title="XML Data Binding" number="15">
<topic name="First Principles" />
<topic name="Castor" />
<topic name="Zeus" />
<topic name="JAXB" />
<topic name="What's Next?" />
</chapter>
<chapter title="Looking Forward" number="16">
<topic name="XLink" />
<topic name="XPointer" />
<topic name="XML Schema Bindings" />
<topic name="And the Rest..." />
<topic name="What's Next?" />
</chapter>
</contents>
<ora:copyright>&OReillyCopyright;</ora:copyright>
</book>
<!DOCTYPE book SYSTEM "DTD/JavaXML.dtd">
<!-- Java and XML Contents -->
<book xmlns="http://www.oreilly.com/javaxml2"
xmlns:ora="http://www.oreilly.com"
>
<title ora:series="Java">Java and XML</title>
<!-- Chapter List -->
<contents>
<chapter title="Introduction" number="1">
<topic name="XML Matters" />
<topic name="What's Important" />
<topic name="The Essentials" />
<topic name="What's Next?" />
</chapter>
<chapter title="Nuts and Bolts" number="2">
<topic name="The Basics" />
<topic name="Constraints" />
<topic name="Transformations" />
<topic name="And More..." />
<topic name="What's Next?" />
</chapter>
<chapter title="SAX" number="3">
<topic name="Getting Prepared" />
<topic name="SAX Readers" />
<topic name="Content Handlers" />
<topic name="Gotcha!" />
<topic name="What's Next?" />
</chapter>
<chapter title="Advanced SAX" number="4">
<topic name="Properties and Features" />
<topic name="More Handlers" />
<topic name="Filters and Writers" />
<topic name="Even More Handlers" />
<topic name="Gotcha!" />
<topic name="What's Next?" />
</chapter>
<chapter title="DOM" number="5">
<topic name="The Document Object Model" />
<topic name="Serialization" />
<topic name="Mutability" />
<topic name="Gotcha!" />
<topic name="What's Next?" />
</chapter>
<chapter title="Advanced DOM" number="6">
<topic name="DOM and Mutation" />
<topic name="Namespaces and DOM Level 2" />
<topic name="DOM and HTML" />
<topic name="DOM Level 3" />
<topic name="Gotcha!" />
<topic name="What's Next?" />
</chapter>
<chapter title="JDOM" number="7">
<topic name="The Basics" />
<topic name="PropsToXML" />
<topic name="XMLProperties" />
<topic name="Is JDOM a Standard?" />
<topic name="Gotcha!" />
<topic name="What's Next?" />
</chapter>
<chapter title="Advanced JDOM" number="8">
<topic name="The Whole Ball of Wax" />
<topic name="JDOM and Factories" />
<topic name="Wrappers and Decorators" />
<topic name="Gotcha!" />
<topic name="What's Next?" />
</chapter>
<chapter title="JAXP" number="9">
<topic name="API or Abstraction?" />
<topic name="JAXP 1.0" />
<topic name="JAXP 1.1" />
<topic name="Gotcha!" />
<topic name="What's Next?" />
</chapter>
<chapter title="Web Publishing Frameworks" number="10">
<topic name="Selecting a Framework" />
<topic name="Installation" />
<topic name="Using a Publishing Framework" />
<topic name="XSP" />
<topic name="Cocoon 2.0 and Beyond" />
<topic name="What's Next?" />
</chapter>
<chapter title="XML-RPC" number="11">
<topic name="RPC Versus RMI" />
<topic name="Saying Hello" />
<topic name="The Real World" />
<topic name="What's Next?" />
</chapter>
<chapter title="SOAP" number="12">
<topic name="Starting Out" />
<topic name="Setting Up" />
<topic name="Getting Dirty" />
<topic name="Going Further" />
<topic name="What's Next?" />
</chapter>
<chapter title="Web Services" number="13">
<topic name="Web Services" />
<topic name="UDDI" />
<topic name="WSDL" />
<topic name="Putting It All Together" />
<topic name="What's Next?" />
</chapter>
<chapter title="Content Syndication" number="14">
<topic name="The Foobar Public Library" />
<topic name="mytechbooks.com" />
<topic name="Push Versus Pull" />
<topic name="What's Next?" />
</chapter>
<chapter title="XML Data Binding" number="15">
<topic name="First Principles" />
<topic name="Castor" />
<topic name="Zeus" />
<topic name="JAXB" />
<topic name="What's Next?" />
</chapter>
<chapter title="Looking Forward" number="16">
<topic name="XLink" />
<topic name="XPointer" />
<topic name="XML Schema Bindings" />
<topic name="And the Rest..." />
<topic name="What's Next?" />
</chapter>
</contents>
<ora:copyright>&OReillyCopyright;</ora:copyright>
</book>
참고로 위 예제는 O'Reilly에서 출판된 'Java and XML 2nd'에 있는 코드이다. 위 XML 문서는 책의 목차를 보여주고 있다는 것을 예상할 수 있을 것이다. 이 XML 문서를 HTML로 변환해줄 XSL 파일은 다음과 같다.
<?xml version="1.0"?>
<xsl:stylesheet xmlns:javaxml2="http://www.oreilly.com/javaxml2"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:ora="http://www.oreilly.com"
version="1.0"
>
<xsl:template match="javaxml2:book">
<xsl:processing-instruction
name="cocoon-format">type="text/html"</xsl:processing-instruction>
<html>
<head>
<title><xsl:value-of select="javaxml2:title" /></title>
</head>
<body>
<xsl:apply-templates select="*[not(self::javaxml2:title)]" />
</body>
</html>
</xsl:template>
<xsl:template match="javaxml2:contents">
<center>
<h2>Table of Contents</h2>
</center>
<hr />
<ul>
<xsl:for-each select="javaxml2:chapter">
<b>
Chapter <xsl:value-of select="@number" />.
<xsl:text> </xsl:text>
<xsl:value-of select="@title" />
</b>
<xsl:for-each select="javaxml2:topic">
<ul>
<li><xsl:value-of select="@name" /></li>
</ul>
</xsl:for-each>
</xsl:for-each>
</ul>
</xsl:template>
<xsl:template match="ora:copyright">
<p align="center"><font size="-1">
<xsl:copy-of select="*" />
</font></p>
</xsl:template>
</xsl:stylesheet>
<xsl:stylesheet xmlns:javaxml2="http://www.oreilly.com/javaxml2"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:ora="http://www.oreilly.com"
version="1.0"
>
<xsl:template match="javaxml2:book">
<xsl:processing-instruction
name="cocoon-format">type="text/html"</xsl:processing-instruction>
<html>
<head>
<title><xsl:value-of select="javaxml2:title" /></title>
</head>
<body>
<xsl:apply-templates select="*[not(self::javaxml2:title)]" />
</body>
</html>
</xsl:template>
<xsl:template match="javaxml2:contents">
<center>
<h2>Table of Contents</h2>
</center>
<hr />
<ul>
<xsl:for-each select="javaxml2:chapter">
<b>
Chapter <xsl:value-of select="@number" />.
<xsl:text> </xsl:text>
<xsl:value-of select="@title" />
</b>
<xsl:for-each select="javaxml2:topic">
<ul>
<li><xsl:value-of select="@name" /></li>
</ul>
</xsl:for-each>
</xsl:for-each>
</ul>
</xsl:template>
<xsl:template match="ora:copyright">
<p align="center"><font size="-1">
<xsl:copy-of select="*" />
</font></p>
</xsl:template>
</xsl:stylesheet>
앞의 XML 문서를 [톰캣]/webapps/cocoon 디렉토리에 contents.xml 로 저장하고, 뒤의 XSL 문서를 [톰캣]/webapps/cocoon/XSL/JavaXML.html.xsl로 저장하자.
contents.xml 파일에서 중요한 점은 contents.xml 파일을 처리할 때 사용되는 XSL 문서를 지정하고 있지 않다는 점이다. 실제로 XML 문서를 변환할 때 사용할 XSL 문서는 코쿤의 설정 파일인 sitemap.xmap 파일에서 지정하게 된다. 이 예제를 지정하기 위해서는 [톰캣]/webapps/cocoon/sitemap.xmap 파일에 다음의 내용을 추가하면 된다.
<map:match pattern="contents.html">
<map:generate src="contents.xml"/>
<map:transform src="XSL/JavaXML.html.xsl"/>
<map:serialize type="html"/>
</map:match>
<map:generate src="contents.xml"/>
<map:transform src="XSL/JavaXML.html.xsl"/>
<map:serialize type="html"/>
</map:match>
여기서 <map:match>는 클라이언트가 요청한 URI와의 매핑되는 조건을 입력하며, <map:generate>은 사용자의 요청에 대해서 사용할 Generator를 지정한다. src 속성의 값이 contents.xml 인데 이는 contents.xml을 사용하여 XML 문서를 생성한다는 것을 의미한다. <map:transform>은 Transformmer를 나타내는 것으로서 XML 문서를 변환할 때 사용할 XSL 문서를 지정한다. 마지막으로 <map:serialize>는 변환된 결과를 렌더링할때 사용되는 Serializer를 나타내는 것으로서, 여기서는 HTML 타입으로 출력해주는 Serializer를 선택하였다.
위 코드를 sitemap.xmap의 다음 부분에 삽입하도록 하자.
<!-- main samples pipeline -->
<map:pipeline>
<map:match pattern="">
<map:generate src="welcome/welcome.xhtml"/>
<map:serialize/>
</map:match>
<map:match pattern="contents.html">
<map:generate src="contents.xml"/>
<map:transform src="XSL/JavaXML.html.xsl"/>
<map:serialize type="html"/>
</map:match>
<map:match pattern="cocoon.gif">
<map:read mime-type="image/gif" src="welcome/cocoon.gif"/>
</map:match>
.....
</map:pipeline>
<map:pipeline>
<map:match pattern="">
<map:generate src="welcome/welcome.xhtml"/>
<map:serialize/>
</map:match>
<map:match pattern="contents.html">
<map:generate src="contents.xml"/>
<map:transform src="XSL/JavaXML.html.xsl"/>
<map:serialize type="html"/>
</map:match>
<map:match pattern="cocoon.gif">
<map:read mime-type="image/gif" src="welcome/cocoon.gif"/>
</map:match>
.....
</map:pipeline>
이제 필요한 설정은 끝났다. 톰캣을 실행하고 웹브라우저를 실행한 다음 웹브라우저의 주소란에 다음과 같은 URL을 입력해보자.
http://localhost/cocoon/contents.html
그러면 다음과 같은 결과 화면이 출력될 것이다.
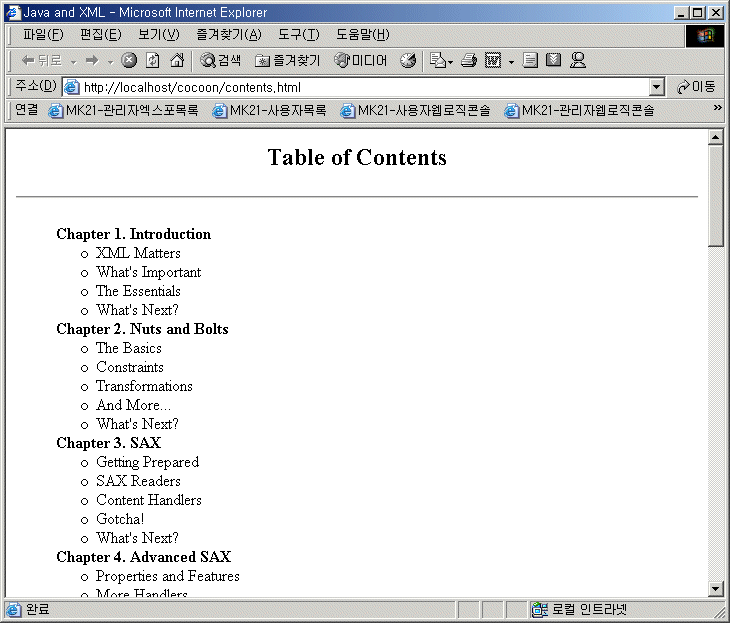
위 출력 결과를 보면 XML 데이터가 HTML로 변환되어 출력된 것을 알 수 있다. 이 출력 결과에서 우리가 알아야 할 점은 컨텐트(XML 문서)와 컨텐트의 출판 방식(XSL 문서)이 서로 분리되어 있다는 점이다. 즉, 컨텐트 제작자와 디자이너의 작업 결과물이 서로 분리되어 있는 것이다. 그리고, 앞으로 살펴볼 XSP를 통해서 로직 부분이 처리되기 때문에, 컨텐트 제작자, 디자이너, 개발자의 작업이 서로 겹치지 않게 된다. 또한, 웹 사이트 관리자는 사이트맵을 통해서 컨텐트, 스타일, XSP를 알맞게 조합할 수 있다. 즉, 코쿤을 사용함으로써 완벽한 업무 분담이 이루어질 수 있는 것이다.
참고로 웹브라우저에 입력한 URL을 보면 contents.xml이 아닌 contents.html을 요청한 것을 알 수 있다. 즉, 클라이언트는 응답결과가 XML을 변환한 문서라는 것을 알 수 없는 것이다. 이처럼 원본 데이터에 대한 정보를 숨길 수 있는 것도 웹 사이트를 운영하는데 있어 유용한 기능중의 하나이다.
결론
이번 글에서는 코쿤에 대한 개략적인 설명과 설치 방법, 그리고 간단하게 나마 예제를 통해서 데이터와 표현부를 분리할 수 있다는 것도 알게 되었다. 다음에는 코쿤이 기본적으로 제공하는 사이트맵 컴포넌트인 Matcher, Generator, Transformer, Serializer에 대해서 살펴보고, 실제로 하나의 컨텐트를 다양한 방식으로 출판하는 예제도 살펴보도록 하자.
관련링크: