





반응형
올바른 코딩 규칙, 클래스의 올바른 사용을 통해 성능 저하 요소를 없앨 수 있으며 오브젝트 풀링을 함께 사용함으로써 어플리케이션의 전체적인 성능을 향상시킬 수 있다.
자바와 성능 문제
오늘날 자바는 엔터프라이즈 시장에서 확고히 자리잡고 있다. MS에서 닷넷이라는 새로운 플랫폼을 내 놓긴 했지만, 현재 비주얼 스튜디오 닷넷 베타 버전이 나와 있을 뿐이며, 기본적인 닷넷 플랫폼은 2002년에 완성될 예정이며, 2005년 정도나 되야 닷넷 플랫폼과 관련된 모든 것들이 완성될 것으로 예상된다. 따라서 향후 몇 년간은 엔터프라이즈 시장에서, 특히 대규모 프로젝트에서는 EJB/서블릿/JSP를 통해 힘을 받은 자바의 독주가 예상되고 있다.
이처럼 자바가 세상의 주도적인 언어로 자리잡아 가고 있지만, 아직도 자바가 헤어나지 못하고 있는 부분이 있다. 그것은 바로 성능과 관련된 문제이다. 실제로 많은 개발자들이 자바가 처음 세상에 나온 이후부터 계속해서 자바의 성능에 대해 불평을 해 왔다. 실제로 자바를 이용하여 잘 작성된 프로그램은 C++/C를 이용하여 잘 작성된 프로그램 만큼의 성능을 내지는 못하는 것이 사실이다. 이것은 자바가 인터프리터 언어라는 점을 감안하면 어쩔 수 없는 것일지도 모르겠다. 하지만, 실제로 자바에서 대부분의 성능 문제는 자바 때문이라기 보다는 프로그램 그 자체에 있다. 올바른 방법으로 프로그래밍을 할 경우 그렇지 않은 경우에 비해 많은 성능 향상을 일으킬 수 있다. 예를 들어, 자바 어플리케이션에서 데이터베이스 커넥션 풀링을 사용할 경우 시스템 자원의 활용도를 높일 수 있을 뿐만 아니라 애플리케이션은 더욱 견고하고 플랫폼에 독립적이게 된다.
이처럼 성능을 향상시키도록 코딩을 하기 위해서는 java.util.Vector나 java.lang.String과 같은 기본적인 부분에서부터 쓰레드 풀링과 데이터베이스 커넥션 풀링과 같은 것들을 전반적으로 확실하게 이해하고 있어야 한다. 이 글에서는 자바 프로그래밍에서 성능을 향상시키기 위한 몇가지 규칙에 대해서 살펴볼 것이다.
String vs. StringBuffer
자바에서 가장 많이 사용되는 것이 있다면 아마 java.lang.String일 것이다. 하지만, String 클래스는 가장 비효율적으로 사용되고 있는 클래스 중의 하나이다. 다음의 코드를 살펴보자.
많은 자바 개발자들은 위 코드가 비효율적이라는 것을 알고 있으며, 이처럼 String을 계속해서 더해나가야 하는 경우에는 StringBuffer 객체를 사용하는 것이 더 좋다는 사실도 알고 있다. 아마 다음과 같이 StringBuffer를 사용하여 위 코드를 대체할 것이다.
아마도 여러분은 StringBuffer를 사용한 위 코드가 앞에서 String 객체를 직접 연결한 것보다 더 효율적이라고 생각할 것이다. 하지만, 그 생각은 틀렸다! 여러분은 아마도 지금 StringBuffer를 사용하는 것이 각각의 String 객체보다 더 효율적이지 않다면, 왜 대부분의 사람들은 StringBuffer를 사용하는 것이 성능이 좋다라고 강조하는 지 의아해 할지도 모른다. 물론, StringBuffer 클래스를 사용하는 것이 각각의 String 객체를 사용하는 것 보다 더 효율적이다. 단, 성능이 좋은 경우는 StringBuffer 클래스를 알맞게 사용했을 때의 얘기이다. 이해를 돕기 위해 StringBuffer 클래스의 기본 생성자를 살펴보자.
위 코드는 StringBuffer가 16개의 글자를 저장할 수 있다는 것을 의미한다. 이제 StringBuffer의 append() 메소드를 살펴보자.
append() 메소드는 먼저 새로 추가할 String의 길이를 구한다. 그리고 현재 StringBuffer에 저장되어 있는 문자열의 길이(count)와 새로 추가할 문자열의 길이(len)의 합이 StringBuffer가 저장할 수 있는 용량(value.length)보다 크면 expandCapacity()를 호출한다. expandCapacity()는 메로리에 새로운 저장 공간을 생성한 후, 기존의 내용을 새로운 공간에 저장한다. 즉, 새로운 객체가 생성되는 것이다. 바로 이 점을 올바르게 알고서 StringBuffer 클래스를 사용해야 한다. 앞에서 StringBuffer를 사용하여 더하고자 하는 문자열은 "Testing String"과 " ", 그리고 "Concatenation Performance" 였다. 이 문자열을 모두 연결하면 " Testing String Concatenation Performance"가 되며, 이것의 길이는 16자가 넘어간다. 따라서 expandCapacity() 메소드를 통해 새로운 객체를 생성하게 되는 것이다. 이렇게 되면 StringBuffer를 사용한 경우나 사용하지 않은 경우나 별 차이가 없게 된다.
그렇다면 어떻게 해야 하는가? 이미 그 해답을 알았을 것이다. 바로 StringBuffer를 생성할 때 알맞은 저장 용량을 지정해주어야 해야 하는 것이다. 즉, 다음과 같이 코드를 변경해주면 된다.
다시 한번 말하지만, StringBuffer의 저장용량을 알맞게 지정해 줄 때에 비로서 효율적으로 메모리를 사용할 수 있다는 점을 기억하자!
java.util.Vector 클래스
String 다음으로 많이 사용되는 클래스가 있다면 바로 java.util.Vector일 것이다. Vector는 객체들을 저장하고 있는 리스트라고 할 수 있다. 배열과 비슷하게, 인덱스를 사용하여 Vector가 저장하고 있는 객체에 접근할 수 있다. 하지만, 배열과 달리 Vector가 저장할 수 있는 객체의 수는 가변적이다. 즉, Vector를 생성한 이후에 새로운 객체를 추가하거나 삭제할 수 있다. 또한, 인덱스를 사용하여 지정된 위치에 객체를 삽입하거나 지정된 위치에 있는 객체를 삭제할 수도 있다. Vector는 객체를 저장하기 위해서 내부적으로 배열을 사용한다. 즉, 배열의 길이가 저장할 수 있는 객체의 수가 되는 것이다. 만약 그 배열의 길이보다 더 많은 수를 저장해야 한다면 어떻게 될까? Vector는 StringBuffer와 비슷하게 기존의 배열보다 더 긴 새로운 배열을 만들고 기존 배열에 있는 내용을 그대로 복사하게 된다. 따라서 Vector를 생성할 때 알맞게 Vector의 저장 용량을 지정해주는 것이 좋다. 참고로 Vector 클래스의 기본 생성자는 저장 용량의 크기를 10으로 한다.
Vector 클래스에서 성능에 또 다른 문제가 될 수 있는 메소드가 바로 add(index, obj) 메소드이다. 여기서 index는 obj 객체를 저장할 인덱스를 나타낸다. 예를 들어, 가장 앞에 새로운 객체를 추가하고 싶다고 해 보자. 이 경우 다음과 같이 프로그램할 것이다.
그렇다면 왜 add(index, obj) 메소드가 문제가 될 수 있는 지 살펴보자. add(index, obj) 메소드는 내부적으로 insertElementAt() 메소드를 호출한다. 이 메소드가 하는 역할을 index 값으로 명시된 위치에 obj 객체를 삽입하는 것이다. 이를 그림으로 도식화하면 다음과 같다.
위 그림에서 ob0 부터 ob4는 이미 Vector에 저장되어 있는 객체를 의미하며, 5번째와 6번째는 어떤 객체도 할당되지 않았음을 나타낸다. Vector의 맨 앞에 객체를 삽입하게 되면, 그림에서 보듯이 0번째 이후에 있는 모든 객체들이 하나씩 뒤로 이동하게 된다. 이렇게 하나씩 뒤로 이동시키기 위해서는 뒤에서부터 차례대로 모든 객체의 위치를 변경해주어야 한다. 위의 그림처럼 Vector에 소수의 객체가 저장되어 있는 경우에는 성능에 별다른 문제가 발생하지 않겠지만, 만약 저장되어 있는 객체가 수천, 수만에 이른다면 중간에 어떤 객체를 삽입하는 것, 특히 맨 앞에 삽입하는 것은 성능에 문제가 될 수 있다. 따라서 어떤 특정한 위치에 반드시 삽입해야 하는 경우가 아니라면 Vector의 맨 뒤에 객체를 삽입하는 것이 성능에 있어 효율적이다.
이와 비슷한 문제가 객체를 삭제할 때에도 발생한다. Vector의 맨 뒤에 있는 객체를 삭제하는 것에 비해 중간에 있는 객체를 삭제하는 것이 아무래도 Vector에 있는 더 많은 객체를 이동하게 만든다. 이말은 맨 앞에 있는 객체를 삭제하는 것에 비해 맨 뒤에 있는 객체를 삭제하는 것이 더 빠르다는 것을 의미한다.
Vector 클래스에서 많이 사용하는 메소드 중의 하나로 indexOf(Object)가 있다. 이 메소드는 특정한 객체가 저장된 인덱스를 구해준다. 성능에 주의를 기울이지 않을 경우, 어떤 특정한 객체를 삭제하기 위해서 indexOf() 메소드를 사용하여 다음과 같이 코딩하는 경우가 있다.
얼핏 보면 위 코드가 별다른 문제가 없는 것으로 보일 것이다. 하지만, indexOf(Object) 메소드와 remove(Object) 메소드는 둘다 순차탐색을 사용한다. indexOf(Object) 메소드를 통해서 이미 obj 객체가 저장된 위치를 알았음에도 불구하고 remove(Object) 메소드에서 또 다시 순차탐색을 하는 것이다. 저장된 객체의 개수가 많을 경우 순차 탐색은 좋은 성능을 발휘하지 못하는데, 이러한 순차탐색을 두번이나 한다는 것은 많은 성능 저하를 일으키는 부분이 될 수 있다. 따라서 이미 삭제할 객체의 인덱스를 알고 있는 경우에는 다음과 같이 remove(int) 메소드를 사용하여 객체를 삭제하는 것이 성능 저하를 일으키지 않는다.
이를 좀더 개선하면 다음과 같다.
Vector 클래스를 사용하여 개발을 하다보면 size() 메소드를 매우 빈번하게 사용하게 된다. size() 메소드를 사용하는 부분 중에는 Vector에 있는 모든 객체를 참조하고 싶은 경우가 많다. 예를 들어, 채팅 프로그램을 개발할 경우 현재 방에 있는 모든 사람한테 특정한 메시지를 보내는 경우가 있는데, 이러한 경우에는 다음과 같은 형태로 프로그래밍하게 된다.
여기서 성능 저하를 일으킬 수 있는 부분은 바로 for ( ; ; ) 문이다. vec.size() 메소드가 for 구문안에 위치함으로써 vec.size() 메소드는 Vector의 크기만큼 호출된다. 만약 십만개의 객체가 저장되어 있다면 size() 메소드도 십만번 호출되는 것이다. 프로그램 코드 중 실제로 전체 수행시간의 70 퍼센트 이상을 for 문이나 while 문과 같은 반복문이 차지한다는 점을 감안해보면 이처럼 반복문에서 같은 값을 구하기 위해 매번 특정한 작업을 수행한다는 것은 성능을 저하시키는 원인이 될 수 있다. 이처럼 반복문에서의 성능 저하를 줄이기 위해서는 위 코드를 다음과 같이 변경해야 한다.
이처럼 간단하게 변경만 해 주어도 여러분이 작성한 애플리케이션은 CPU를 좀 더 효과적으로 사용할 수 있게 된다.
객체의 재활용: 오브젝트 풀링
오늘날 많은 웹 어플리케이션을 개발할 때 많이 사용되는 제품이 바로 어플리케이션 서버이다. BEA의 웹로직이나 IBM의 웹스피어와 같은 제품이 바로 어플리케이션 서버이다. 이러한 어플리케이션 서버들은 대부분 은행이나 증권 사이트와 같은 대형 프로젝트에서 사용되고 있다. 이러한 대형 사이트는 동시 접속자 수가 수백/수천/수만에 이르며, 따라서 어플리케이션 서버는 성능을 향상시키기 위해 내부적으로 많은 것들을 지원하고 있다. 어플리케이션 서버들이 성능을 향상시키기 위해 많이 사용하는 것 중의 하나가 바로 오브젝트 풀링이다. 오브젝트 풀링이 가장 많이 사용되는 부분을 손꼽으라면 데이터베이스 커넥션 풀링, 쓰레드 풀링 그리고 EJB에서의 빈 컴포넌트 풀링이다. 특히 데이터베이스 커넥션 풀링은 어플리케이션 서버를 사용하지 않는 프로젝트에서도 성능을 향상시키기 위해 많이 사용되고 있다.
오브젝트 풀링은 기존에 생성된 객체를 재사용하는 것이 주목적이다. 오브젝트 풀링의 기본 형태는 풀(pool)로부터 미리 생성해 놓은 객체를 구해서 사용하고, 사용이 끝나면 다시 그 객체를 풀 속에 넣는 것이다. 즉, 풀은 사용가능한 객체를 저장하고 있는 저장소가 된다. 이 글에서는 오브젝트 풀링을 어떻게 구현하는 지에 대해서는 언급하지 않을 것이다. 각각의 풀링이 어떻게 구현하는 지 알고 싶은 사람은 관련 링크를 참고하기 바란다. 가장 많이 사용되는 데이터 베이스 커넥션 풀링과 쓰레드 풀링이 어떻게 어플리케이션의 성능을 향상시켜주는 지에 대해서 알아보자.
데이터베이스 커넥션 풀링
오늘날 웹 어플리케이션을 비롯한 대부분의 어플리케이션이 데이터베이스에 데이터를 저장하고 데이터베이스로부터 데이터를 읽어온다. 일반적으로 데이터베이스를 사용하기 위해서는 "데이터베이스 연결 - 필요한 작업 수행 - 연결 해제"의 3 단계를 거치게 된다. 여기서 데이터베이스에 연결할 때는 적지 않은 시간을 필요로 한다. 특히 어플리케이션과 데이터베이스가 서로 다른 호스트에 존재할 경우에는 데이터베이스에 연결하기 위해서 소켓접속을 필요로 하며 따라서 그 만큼 더 많은 시간을 필요로 한다. 동시 사용자 수가 적을 경우에는 별다른 문제가 발생하지 않을 수도 있지만, 동시 사용자 수가 수백, 수천명에 이른다면? (여기서 동시 사용자는 1초보다도 더 적은 시간에 접속하는 사용자의 수를 의미한다). 어플리케이션은 수백 수천의 요청에 대해 각각 하나씩의 데이터베이스 커넥션을 생성하려 할 것이다. 하지만, 이렇게 수백, 수천의 커넥션을 동시에 생성하기 위해서는 많은 시간을 필요로 하며, 시스템 자원 역시 상당량 소모될 것이다.
데이터베이스 커넥션 풀링은 이처럼 데이터베이스에 연결하기 위해 소모되는 시간을 줄임으로써 어플리케이션이 클라이언트의 요청에 대해 빠르게 응답할 수 있도록 해 준다. 뿐만 아니라 동시에 접속되어 있는 커넥션의 개수를 일정하게 유지함으로써 시스템 자원을 효과적으로 사용할 수 있게 된다.
쓰레드 풀링
웹 어플리케이션을 개발하는 경우 쓰레드 풀링을 직접적으로 사용해야 하는 경우는 극히 드물다고 할 수 있다. 하지만, 웹 서버나 파일서버, 또는 어플리케이션 서버와 같이 동시에 많은 양의 클라이언트 요청을 처리해야 하는 경우에는 상황이 좀 다르다. 예를 들어, 여러분의 웹 서버에 동시에 100명이 서비스를 요청했다고 해 보자. 여러분이 사용하는 웹 서버가 쓰레드 풀링을 사용하지 않는다면 각각의 클라이언트에 대해서 한 개의 쓰레드가 생성될 것이다. 즉, 100개의 쓰레드가 생성되는 것이다. 자바 가상 머신의 구현에 따라 다르지만 하나의 쓰레드가 많을 경우 200k 정도의 메모리를 차지한다. 따라서 100개의 쓰레드를 사용하려면 20,000K 정도의 메모리가 필요한 것이다. 이 수치는 20M에 가까운 수치다. 대형 웹 사이트의 경우 매 순간마다 천명 이상의 요청이 웹 서버에 들어올 수 있으며, 만약 하나의 요청당 하나의 쓰레드가 생성된다면 쓰레드를 생성하는 데 드는 메모리만 200M 이상의 될 수 있다. 여기서 더욱 문제가 되는 점은 쓰레드의 실행이 종료되어도 쓰레드와 관련된 객체들이 곧 바로 가비지 콜렉션되지 않고 메모리에 남아 있다는 점이다. 클라이언트의 요청은 계속해서 들어올 것이며, 기존에 생성된 쓰레드와 관련된 객체는 가비지로 남아 있는 채, 또 다른 객체를 메모리에 할당하게 된다. 따라서, 빠른 시간내에 메모리는 가비지로 차게 되며, 이는 빈번한 가비지 콜렉션을 발생시키는 원인이 된다. 즉, 쓰레드를 생성하고 가비지 콜렉션을 수행하는 데 적지 않은 시간이 소모되는 것이다. 또한, 수백/수천개의 쓰레드가 생성되면 자바 가상 머신은 그러한 쓰레드를 스케쥴링 하는데 많은 시간을 소모하게 된다. 쓰레드를 스케쥴링하는 데 CPU를 많이 사용하면 그 만큼 실제 작업을 수행할 수 있는 시간이 줄어들게 되는 것이며, 이는 사용자의 요청에 대한 느린 응답으로 연결된다. 결과적으로 배보다 배꼽이 더 큰 상황이 발생하는 것이다.
쓰레드와 관련된 성능 저하는 쓰레드 풀링을 사용함으로써 많은 부분 해결할 수 있다. 미리 풀 속에 사용가능한 쓰레드를 일정 개수 생성한 후, 쓰레드가 필요할 때 마다 풀에 저장되어 있는 풀을 사용하기 때문에 쓰레드를 생성하는 데 소비되는 시간을 줄일 수 있으며, 따라서 쓰레드 관련 객체의 생성/삭제에 따른 가비지 객체의 생성 및 빈번한 가비지 콜렉션 수행에 따른 시간 소비를 줄일 수 있다. 또한, 일정 개수만큼의 쓰레드만을 유지하기 때문에 쓰레드를 스케쥴링 하는 데 소비되는 시간도 일정하다. 이처럼 불필요하게 낭비되는 시간을 줄임으로써 어플리케이션은 클라이언트의 요청에 대해 좀 더 빠르게 응답할 수 있을 것이다.
결론
이번 글에서는 좋은 코딩 규칙을 통해서 성능 저하 부분을 없애고 오브젝트 풀링을 통해서 성능을 향상시키는 것에 대해서 알아보았다. 여기서 코딩 규칙과 관련된 부분은 대다수의 개발자들이 쉽게 간과하는 부분이지만, 코딩을 조금만 더 신경써서 하면 성능 저하를 상당히 줄일 수 있다는 점에서 매우 중요하다고 할 수 있다. 특히, String, StringBuffer 그리고 Vector와 같이 많이 사용되는 클래스가 내부적으로 어떻게 동작하는 지 알고 있어야 하며, 그렇게 함으로써 적은 노력으로 성능 저하 요소를 상당부분 없앨 수 있다. 코딩 규칙 뿐만 아니라 오브젝트 풀링을 사용함으로써 전체적인 어플리케이션의 응답속도가 향상될 뿐 아니라 전체적인 어플리케이션의 처리량, 즉 throughput을 증가시킬 수 있다.
이제, 자신들이 만든 어플리케이션이 성능이 좋지 않다고 해서 무턱대고 자바를 탓해서는 안 되는 때가 온거 같다는 생각이 든다. 이제, 자바 개발자들은 올바른 코딩 습관을 몸에 익히고 클래스를 올바르게 사용함으로써 개발하는 어플리케이션의 성능 저하 요소를 없애야 하며, 또한 오브젝트 풀링을 비롯한 다양한 방법을 통해서 성능 향상을 꾀할 수 있도록 노력해야 한다.
관련링크:
자바와 성능 문제
오늘날 자바는 엔터프라이즈 시장에서 확고히 자리잡고 있다. MS에서 닷넷이라는 새로운 플랫폼을 내 놓긴 했지만, 현재 비주얼 스튜디오 닷넷 베타 버전이 나와 있을 뿐이며, 기본적인 닷넷 플랫폼은 2002년에 완성될 예정이며, 2005년 정도나 되야 닷넷 플랫폼과 관련된 모든 것들이 완성될 것으로 예상된다. 따라서 향후 몇 년간은 엔터프라이즈 시장에서, 특히 대규모 프로젝트에서는 EJB/서블릿/JSP를 통해 힘을 받은 자바의 독주가 예상되고 있다.
이처럼 자바가 세상의 주도적인 언어로 자리잡아 가고 있지만, 아직도 자바가 헤어나지 못하고 있는 부분이 있다. 그것은 바로 성능과 관련된 문제이다. 실제로 많은 개발자들이 자바가 처음 세상에 나온 이후부터 계속해서 자바의 성능에 대해 불평을 해 왔다. 실제로 자바를 이용하여 잘 작성된 프로그램은 C++/C를 이용하여 잘 작성된 프로그램 만큼의 성능을 내지는 못하는 것이 사실이다. 이것은 자바가 인터프리터 언어라는 점을 감안하면 어쩔 수 없는 것일지도 모르겠다. 하지만, 실제로 자바에서 대부분의 성능 문제는 자바 때문이라기 보다는 프로그램 그 자체에 있다. 올바른 방법으로 프로그래밍을 할 경우 그렇지 않은 경우에 비해 많은 성능 향상을 일으킬 수 있다. 예를 들어, 자바 어플리케이션에서 데이터베이스 커넥션 풀링을 사용할 경우 시스템 자원의 활용도를 높일 수 있을 뿐만 아니라 애플리케이션은 더욱 견고하고 플랫폼에 독립적이게 된다.
이처럼 성능을 향상시키도록 코딩을 하기 위해서는 java.util.Vector나 java.lang.String과 같은 기본적인 부분에서부터 쓰레드 풀링과 데이터베이스 커넥션 풀링과 같은 것들을 전반적으로 확실하게 이해하고 있어야 한다. 이 글에서는 자바 프로그래밍에서 성능을 향상시키기 위한 몇가지 규칙에 대해서 살펴볼 것이다.
String vs. StringBuffer
자바에서 가장 많이 사용되는 것이 있다면 아마 java.lang.String일 것이다. 하지만, String 클래스는 가장 비효율적으로 사용되고 있는 클래스 중의 하나이다. 다음의 코드를 살펴보자.
String s1 = "Testing String";
String s2 = "Concatenation Performance";
String s3 = s1 + " " + s2;
String s2 = "Concatenation Performance";
String s3 = s1 + " " + s2;
많은 자바 개발자들은 위 코드가 비효율적이라는 것을 알고 있으며, 이처럼 String을 계속해서 더해나가야 하는 경우에는 StringBuffer 객체를 사용하는 것이 더 좋다는 사실도 알고 있다. 아마 다음과 같이 StringBuffer를 사용하여 위 코드를 대체할 것이다.
StringBuffer s = new StringBuffer();
s.append("Testing String");
s.append(" ");
s.append("Concatenation Performance");
String s3 = s.toString();
s.append("Testing String");
s.append(" ");
s.append("Concatenation Performance");
String s3 = s.toString();
아마도 여러분은 StringBuffer를 사용한 위 코드가 앞에서 String 객체를 직접 연결한 것보다 더 효율적이라고 생각할 것이다. 하지만, 그 생각은 틀렸다! 여러분은 아마도 지금 StringBuffer를 사용하는 것이 각각의 String 객체보다 더 효율적이지 않다면, 왜 대부분의 사람들은 StringBuffer를 사용하는 것이 성능이 좋다라고 강조하는 지 의아해 할지도 모른다. 물론, StringBuffer 클래스를 사용하는 것이 각각의 String 객체를 사용하는 것 보다 더 효율적이다. 단, 성능이 좋은 경우는 StringBuffer 클래스를 알맞게 사용했을 때의 얘기이다. 이해를 돕기 위해 StringBuffer 클래스의 기본 생성자를 살펴보자.
public StringBuffer() {
this(16);
}
this(16);
}
위 코드는 StringBuffer가 16개의 글자를 저장할 수 있다는 것을 의미한다. 이제 StringBuffer의 append() 메소드를 살펴보자.
public synchronized StringBuffer append(String str) {
if (str == null) {
str = String.valueOf(str);
}
int len = str.length();
int newcount = count + len;
if (newcount > value.length)
expandCapacity(newcount);
str.getChars(0, len, value, count);
count = newcount;
return this;
}
if (str == null) {
str = String.valueOf(str);
}
int len = str.length();
int newcount = count + len;
if (newcount > value.length)
expandCapacity(newcount);
str.getChars(0, len, value, count);
count = newcount;
return this;
}
append() 메소드는 먼저 새로 추가할 String의 길이를 구한다. 그리고 현재 StringBuffer에 저장되어 있는 문자열의 길이(count)와 새로 추가할 문자열의 길이(len)의 합이 StringBuffer가 저장할 수 있는 용량(value.length)보다 크면 expandCapacity()를 호출한다. expandCapacity()는 메로리에 새로운 저장 공간을 생성한 후, 기존의 내용을 새로운 공간에 저장한다. 즉, 새로운 객체가 생성되는 것이다. 바로 이 점을 올바르게 알고서 StringBuffer 클래스를 사용해야 한다. 앞에서 StringBuffer를 사용하여 더하고자 하는 문자열은 "Testing String"과 " ", 그리고 "Concatenation Performance" 였다. 이 문자열을 모두 연결하면 " Testing String Concatenation Performance"가 되며, 이것의 길이는 16자가 넘어간다. 따라서 expandCapacity() 메소드를 통해 새로운 객체를 생성하게 되는 것이다. 이렇게 되면 StringBuffer를 사용한 경우나 사용하지 않은 경우나 별 차이가 없게 된다.
그렇다면 어떻게 해야 하는가? 이미 그 해답을 알았을 것이다. 바로 StringBuffer를 생성할 때 알맞은 저장 용량을 지정해주어야 해야 하는 것이다. 즉, 다음과 같이 코드를 변경해주면 된다.
StringBuffer s = new StringBuffer(45);
s.append("Testing String");
s.append(" ");
s.append("Concatenation Performance");
String s3 = s.toString();
s.append("Testing String");
s.append(" ");
s.append("Concatenation Performance");
String s3 = s.toString();
다시 한번 말하지만, StringBuffer의 저장용량을 알맞게 지정해 줄 때에 비로서 효율적으로 메모리를 사용할 수 있다는 점을 기억하자!
java.util.Vector 클래스
String 다음으로 많이 사용되는 클래스가 있다면 바로 java.util.Vector일 것이다. Vector는 객체들을 저장하고 있는 리스트라고 할 수 있다. 배열과 비슷하게, 인덱스를 사용하여 Vector가 저장하고 있는 객체에 접근할 수 있다. 하지만, 배열과 달리 Vector가 저장할 수 있는 객체의 수는 가변적이다. 즉, Vector를 생성한 이후에 새로운 객체를 추가하거나 삭제할 수 있다. 또한, 인덱스를 사용하여 지정된 위치에 객체를 삽입하거나 지정된 위치에 있는 객체를 삭제할 수도 있다. Vector는 객체를 저장하기 위해서 내부적으로 배열을 사용한다. 즉, 배열의 길이가 저장할 수 있는 객체의 수가 되는 것이다. 만약 그 배열의 길이보다 더 많은 수를 저장해야 한다면 어떻게 될까? Vector는 StringBuffer와 비슷하게 기존의 배열보다 더 긴 새로운 배열을 만들고 기존 배열에 있는 내용을 그대로 복사하게 된다. 따라서 Vector를 생성할 때 알맞게 Vector의 저장 용량을 지정해주는 것이 좋다. 참고로 Vector 클래스의 기본 생성자는 저장 용량의 크기를 10으로 한다.
Vector 클래스에서 성능에 또 다른 문제가 될 수 있는 메소드가 바로 add(index, obj) 메소드이다. 여기서 index는 obj 객체를 저장할 인덱스를 나타낸다. 예를 들어, 가장 앞에 새로운 객체를 추가하고 싶다고 해 보자. 이 경우 다음과 같이 프로그램할 것이다.
Object obj = new Object();
Vector v = new Vector(7);
v.add(0, obj);
Vector v = new Vector(7);
v.add(0, obj);
그렇다면 왜 add(index, obj) 메소드가 문제가 될 수 있는 지 살펴보자. add(index, obj) 메소드는 내부적으로 insertElementAt() 메소드를 호출한다. 이 메소드가 하는 역할을 index 값으로 명시된 위치에 obj 객체를 삽입하는 것이다. 이를 그림으로 도식화하면 다음과 같다.
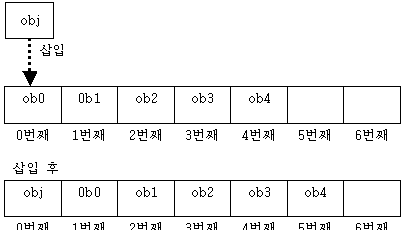
위 그림에서 ob0 부터 ob4는 이미 Vector에 저장되어 있는 객체를 의미하며, 5번째와 6번째는 어떤 객체도 할당되지 않았음을 나타낸다. Vector의 맨 앞에 객체를 삽입하게 되면, 그림에서 보듯이 0번째 이후에 있는 모든 객체들이 하나씩 뒤로 이동하게 된다. 이렇게 하나씩 뒤로 이동시키기 위해서는 뒤에서부터 차례대로 모든 객체의 위치를 변경해주어야 한다. 위의 그림처럼 Vector에 소수의 객체가 저장되어 있는 경우에는 성능에 별다른 문제가 발생하지 않겠지만, 만약 저장되어 있는 객체가 수천, 수만에 이른다면 중간에 어떤 객체를 삽입하는 것, 특히 맨 앞에 삽입하는 것은 성능에 문제가 될 수 있다. 따라서 어떤 특정한 위치에 반드시 삽입해야 하는 경우가 아니라면 Vector의 맨 뒤에 객체를 삽입하는 것이 성능에 있어 효율적이다.
이와 비슷한 문제가 객체를 삭제할 때에도 발생한다. Vector의 맨 뒤에 있는 객체를 삭제하는 것에 비해 중간에 있는 객체를 삭제하는 것이 아무래도 Vector에 있는 더 많은 객체를 이동하게 만든다. 이말은 맨 앞에 있는 객체를 삭제하는 것에 비해 맨 뒤에 있는 객체를 삭제하는 것이 더 빠르다는 것을 의미한다.
Vector 클래스에서 많이 사용하는 메소드 중의 하나로 indexOf(Object)가 있다. 이 메소드는 특정한 객체가 저장된 인덱스를 구해준다. 성능에 주의를 기울이지 않을 경우, 어떤 특정한 객체를 삭제하기 위해서 indexOf() 메소드를 사용하여 다음과 같이 코딩하는 경우가 있다.
얼핏 보면 위 코드가 별다른 문제가 없는 것으로 보일 것이다. 하지만, indexOf(Object) 메소드와 remove(Object) 메소드는 둘다 순차탐색을 사용한다. indexOf(Object) 메소드를 통해서 이미 obj 객체가 저장된 위치를 알았음에도 불구하고 remove(Object) 메소드에서 또 다시 순차탐색을 하는 것이다. 저장된 객체의 개수가 많을 경우 순차 탐색은 좋은 성능을 발휘하지 못하는데, 이러한 순차탐색을 두번이나 한다는 것은 많은 성능 저하를 일으키는 부분이 될 수 있다. 따라서 이미 삭제할 객체의 인덱스를 알고 있는 경우에는 다음과 같이 remove(int) 메소드를 사용하여 객체를 삭제하는 것이 성능 저하를 일으키지 않는다.
SomObject obj = ...;
int i = v.indexOf(obj);
if(i != -1)
v.remove(i);
int i = v.indexOf(obj);
if(i != -1)
v.remove(i);
이를 좀더 개선하면 다음과 같다.
SomObject obj = ...;
v.remove(s);
v.remove(s);
Vector 클래스를 사용하여 개발을 하다보면 size() 메소드를 매우 빈번하게 사용하게 된다. size() 메소드를 사용하는 부분 중에는 Vector에 있는 모든 객체를 참조하고 싶은 경우가 많다. 예를 들어, 채팅 프로그램을 개발할 경우 현재 방에 있는 모든 사람한테 특정한 메시지를 보내는 경우가 있는데, 이러한 경우에는 다음과 같은 형태로 프로그래밍하게 된다.
for (int i = 0 ; i < vec.size() ; i++ ) {
ChatServerWorker worker = (ChatServerWorker) vec.get(i);
worker.sendMessage("...");
}
ChatServerWorker worker = (ChatServerWorker) vec.get(i);
worker.sendMessage("...");
}
여기서 성능 저하를 일으킬 수 있는 부분은 바로 for ( ; ; ) 문이다. vec.size() 메소드가 for 구문안에 위치함으로써 vec.size() 메소드는 Vector의 크기만큼 호출된다. 만약 십만개의 객체가 저장되어 있다면 size() 메소드도 십만번 호출되는 것이다. 프로그램 코드 중 실제로 전체 수행시간의 70 퍼센트 이상을 for 문이나 while 문과 같은 반복문이 차지한다는 점을 감안해보면 이처럼 반복문에서 같은 값을 구하기 위해 매번 특정한 작업을 수행한다는 것은 성능을 저하시키는 원인이 될 수 있다. 이처럼 반복문에서의 성능 저하를 줄이기 위해서는 위 코드를 다음과 같이 변경해야 한다.
int s = vec.size();
for (int i = 0 ; i < s ; i++ ) {
ChatServerWorker cp = (ChatServerWorker) vec.get(i);
worker.sendMessage("...");
}
for (int i = 0 ; i < s ; i++ ) {
ChatServerWorker cp = (ChatServerWorker) vec.get(i);
worker.sendMessage("...");
}
이처럼 간단하게 변경만 해 주어도 여러분이 작성한 애플리케이션은 CPU를 좀 더 효과적으로 사용할 수 있게 된다.
객체의 재활용: 오브젝트 풀링
오늘날 많은 웹 어플리케이션을 개발할 때 많이 사용되는 제품이 바로 어플리케이션 서버이다. BEA의 웹로직이나 IBM의 웹스피어와 같은 제품이 바로 어플리케이션 서버이다. 이러한 어플리케이션 서버들은 대부분 은행이나 증권 사이트와 같은 대형 프로젝트에서 사용되고 있다. 이러한 대형 사이트는 동시 접속자 수가 수백/수천/수만에 이르며, 따라서 어플리케이션 서버는 성능을 향상시키기 위해 내부적으로 많은 것들을 지원하고 있다. 어플리케이션 서버들이 성능을 향상시키기 위해 많이 사용하는 것 중의 하나가 바로 오브젝트 풀링이다. 오브젝트 풀링이 가장 많이 사용되는 부분을 손꼽으라면 데이터베이스 커넥션 풀링, 쓰레드 풀링 그리고 EJB에서의 빈 컴포넌트 풀링이다. 특히 데이터베이스 커넥션 풀링은 어플리케이션 서버를 사용하지 않는 프로젝트에서도 성능을 향상시키기 위해 많이 사용되고 있다.
오브젝트 풀링은 기존에 생성된 객체를 재사용하는 것이 주목적이다. 오브젝트 풀링의 기본 형태는 풀(pool)로부터 미리 생성해 놓은 객체를 구해서 사용하고, 사용이 끝나면 다시 그 객체를 풀 속에 넣는 것이다. 즉, 풀은 사용가능한 객체를 저장하고 있는 저장소가 된다. 이 글에서는 오브젝트 풀링을 어떻게 구현하는 지에 대해서는 언급하지 않을 것이다. 각각의 풀링이 어떻게 구현하는 지 알고 싶은 사람은 관련 링크를 참고하기 바란다. 가장 많이 사용되는 데이터 베이스 커넥션 풀링과 쓰레드 풀링이 어떻게 어플리케이션의 성능을 향상시켜주는 지에 대해서 알아보자.
데이터베이스 커넥션 풀링
오늘날 웹 어플리케이션을 비롯한 대부분의 어플리케이션이 데이터베이스에 데이터를 저장하고 데이터베이스로부터 데이터를 읽어온다. 일반적으로 데이터베이스를 사용하기 위해서는 "데이터베이스 연결 - 필요한 작업 수행 - 연결 해제"의 3 단계를 거치게 된다. 여기서 데이터베이스에 연결할 때는 적지 않은 시간을 필요로 한다. 특히 어플리케이션과 데이터베이스가 서로 다른 호스트에 존재할 경우에는 데이터베이스에 연결하기 위해서 소켓접속을 필요로 하며 따라서 그 만큼 더 많은 시간을 필요로 한다. 동시 사용자 수가 적을 경우에는 별다른 문제가 발생하지 않을 수도 있지만, 동시 사용자 수가 수백, 수천명에 이른다면? (여기서 동시 사용자는 1초보다도 더 적은 시간에 접속하는 사용자의 수를 의미한다). 어플리케이션은 수백 수천의 요청에 대해 각각 하나씩의 데이터베이스 커넥션을 생성하려 할 것이다. 하지만, 이렇게 수백, 수천의 커넥션을 동시에 생성하기 위해서는 많은 시간을 필요로 하며, 시스템 자원 역시 상당량 소모될 것이다.
데이터베이스 커넥션 풀링은 이처럼 데이터베이스에 연결하기 위해 소모되는 시간을 줄임으로써 어플리케이션이 클라이언트의 요청에 대해 빠르게 응답할 수 있도록 해 준다. 뿐만 아니라 동시에 접속되어 있는 커넥션의 개수를 일정하게 유지함으로써 시스템 자원을 효과적으로 사용할 수 있게 된다.
쓰레드 풀링
웹 어플리케이션을 개발하는 경우 쓰레드 풀링을 직접적으로 사용해야 하는 경우는 극히 드물다고 할 수 있다. 하지만, 웹 서버나 파일서버, 또는 어플리케이션 서버와 같이 동시에 많은 양의 클라이언트 요청을 처리해야 하는 경우에는 상황이 좀 다르다. 예를 들어, 여러분의 웹 서버에 동시에 100명이 서비스를 요청했다고 해 보자. 여러분이 사용하는 웹 서버가 쓰레드 풀링을 사용하지 않는다면 각각의 클라이언트에 대해서 한 개의 쓰레드가 생성될 것이다. 즉, 100개의 쓰레드가 생성되는 것이다. 자바 가상 머신의 구현에 따라 다르지만 하나의 쓰레드가 많을 경우 200k 정도의 메모리를 차지한다. 따라서 100개의 쓰레드를 사용하려면 20,000K 정도의 메모리가 필요한 것이다. 이 수치는 20M에 가까운 수치다. 대형 웹 사이트의 경우 매 순간마다 천명 이상의 요청이 웹 서버에 들어올 수 있으며, 만약 하나의 요청당 하나의 쓰레드가 생성된다면 쓰레드를 생성하는 데 드는 메모리만 200M 이상의 될 수 있다. 여기서 더욱 문제가 되는 점은 쓰레드의 실행이 종료되어도 쓰레드와 관련된 객체들이 곧 바로 가비지 콜렉션되지 않고 메모리에 남아 있다는 점이다. 클라이언트의 요청은 계속해서 들어올 것이며, 기존에 생성된 쓰레드와 관련된 객체는 가비지로 남아 있는 채, 또 다른 객체를 메모리에 할당하게 된다. 따라서, 빠른 시간내에 메모리는 가비지로 차게 되며, 이는 빈번한 가비지 콜렉션을 발생시키는 원인이 된다. 즉, 쓰레드를 생성하고 가비지 콜렉션을 수행하는 데 적지 않은 시간이 소모되는 것이다. 또한, 수백/수천개의 쓰레드가 생성되면 자바 가상 머신은 그러한 쓰레드를 스케쥴링 하는데 많은 시간을 소모하게 된다. 쓰레드를 스케쥴링하는 데 CPU를 많이 사용하면 그 만큼 실제 작업을 수행할 수 있는 시간이 줄어들게 되는 것이며, 이는 사용자의 요청에 대한 느린 응답으로 연결된다. 결과적으로 배보다 배꼽이 더 큰 상황이 발생하는 것이다.
쓰레드와 관련된 성능 저하는 쓰레드 풀링을 사용함으로써 많은 부분 해결할 수 있다. 미리 풀 속에 사용가능한 쓰레드를 일정 개수 생성한 후, 쓰레드가 필요할 때 마다 풀에 저장되어 있는 풀을 사용하기 때문에 쓰레드를 생성하는 데 소비되는 시간을 줄일 수 있으며, 따라서 쓰레드 관련 객체의 생성/삭제에 따른 가비지 객체의 생성 및 빈번한 가비지 콜렉션 수행에 따른 시간 소비를 줄일 수 있다. 또한, 일정 개수만큼의 쓰레드만을 유지하기 때문에 쓰레드를 스케쥴링 하는 데 소비되는 시간도 일정하다. 이처럼 불필요하게 낭비되는 시간을 줄임으로써 어플리케이션은 클라이언트의 요청에 대해 좀 더 빠르게 응답할 수 있을 것이다.
결론
이번 글에서는 좋은 코딩 규칙을 통해서 성능 저하 부분을 없애고 오브젝트 풀링을 통해서 성능을 향상시키는 것에 대해서 알아보았다. 여기서 코딩 규칙과 관련된 부분은 대다수의 개발자들이 쉽게 간과하는 부분이지만, 코딩을 조금만 더 신경써서 하면 성능 저하를 상당히 줄일 수 있다는 점에서 매우 중요하다고 할 수 있다. 특히, String, StringBuffer 그리고 Vector와 같이 많이 사용되는 클래스가 내부적으로 어떻게 동작하는 지 알고 있어야 하며, 그렇게 함으로써 적은 노력으로 성능 저하 요소를 상당부분 없앨 수 있다. 코딩 규칙 뿐만 아니라 오브젝트 풀링을 사용함으로써 전체적인 어플리케이션의 응답속도가 향상될 뿐 아니라 전체적인 어플리케이션의 처리량, 즉 throughput을 증가시킬 수 있다.
이제, 자신들이 만든 어플리케이션이 성능이 좋지 않다고 해서 무턱대고 자바를 탓해서는 안 되는 때가 온거 같다는 생각이 든다. 이제, 자바 개발자들은 올바른 코딩 습관을 몸에 익히고 클래스를 올바르게 사용함으로써 개발하는 어플리케이션의 성능 저하 요소를 없애야 하며, 또한 오브젝트 풀링을 비롯한 다양한 방법을 통해서 성능 향상을 꾀할 수 있도록 노력해야 한다.
관련링크: